2020年5月27日 星期三
getopt()的使用
至少三十年沒有用這個Call了,除了Function的大致的功能,其他都忘記了。
第一: 先要在前面加Include:
#include <unistd.h>
Call的格式如下:
int getopt (int Argc, char * const Argv[], const char *Optstring);
前面兩個參數int Argc, char * const Argv[],就是 main()由 Shell 傳進來的兩個參數。
optstring 就是這個Function的精華。
如果 "a:bcf:"。代表要接受的option有 -a, -b, -c。
其中option a的後面還有":"號,代表 -a 這個Flag的後面還有一個參數。
例如 -f filename 也是上面的四個參數的用法。
getopt()提供兩個global variable : optarg 與 optopt。用來輔助getopt()這個function。
遇到像 f: 這樣的參數,getopt()會將 -f 後面的字串放到optarg中。
考慮以下這個命令:
# cdr -a -d -f Filename.log
Usage:
-a : print all information
-c: print non-zero information only, but only raw data (cvs format)
-d: print device_name
-f: Filename.log
--------------------------------------------------------------------------------------
#include <stdio.h>
#include <unistd.h>
int main(int argc, char **argv)
{
int ch;
int Opt_a = 0;
int Opt_c = 0;
int Opt_d = 0;
int option = 0 ;
while ((ch=getopt(argc,argv,"acdf:"))!=-1)
{
switch(ch)
{
case 'a':
Opt_a = 1 ;
option = 1 ;
printf("optiona a is on \n");
break;
case 'c':
Opt_c = 1 ;
option = 1 ;
printf("optiona c is on\n");
break;
case 'd':
Opt_d = 1 ;
option = 1 ;
printf("optiona d is on\n");
break;
case 'f':
printf("option f\n");
option = 1 ;
printf("Filename: %s\n",optarg);
break;
default:
printf("Usage: \n") ;
break;
} /* end of switch */
} /* end of while */
}
-----------------------------------------------------------------------------------------
# cc t.c <Enter>
# ./a.out -d -f filename -a -c <Enter>
optiona d is on
option f
Filename: filename
optiona a is on
optiona c is on
#
第一: 先要在前面加Include:
#include <unistd.h>
Call的格式如下:
int getopt (int Argc, char * const Argv[], const char *Optstring);
前面兩個參數int Argc, char * const Argv[],就是 main()由 Shell 傳進來的兩個參數。
optstring 就是這個Function的精華。
如果 "a:bcf:"。代表要接受的option有 -a, -b, -c。
其中option a的後面還有":"號,代表 -a 這個Flag的後面還有一個參數。
例如 -f filename 也是上面的四個參數的用法。
getopt()提供兩個global variable : optarg 與 optopt。用來輔助getopt()這個function。
遇到像 f: 這樣的參數,getopt()會將 -f 後面的字串放到optarg中。
考慮以下這個命令:
# cdr -a -d -f Filename.log
Usage:
-a : print all information
-c: print non-zero information only, but only raw data (cvs format)
-d: print device_name
-f: Filename.log
--------------------------------------------------------------------------------------
#include <stdio.h>
#include <unistd.h>
int main(int argc, char **argv)
{
int ch;
int Opt_a = 0;
int Opt_c = 0;
int Opt_d = 0;
int option = 0 ;
while ((ch=getopt(argc,argv,"acdf:"))!=-1)
{
switch(ch)
{
case 'a':
Opt_a = 1 ;
option = 1 ;
printf("optiona a is on \n");
break;
case 'c':
Opt_c = 1 ;
option = 1 ;
printf("optiona c is on\n");
break;
case 'd':
Opt_d = 1 ;
option = 1 ;
printf("optiona d is on\n");
break;
case 'f':
printf("option f\n");
option = 1 ;
printf("Filename: %s\n",optarg);
break;
default:
printf("Usage: \n") ;
break;
} /* end of switch */
} /* end of while */
}
-----------------------------------------------------------------------------------------
# cc t.c <Enter>
# ./a.out -d -f filename -a -c <Enter>
optiona d is on
option f
Filename: filename
optiona a is on
optiona c is on
#
2020年5月23日 星期六
Linux network stack: UDP接收端的工作流程
由於發生UDP掉包,於是想要複習一下UDP的程式。先看一下UDP的封包架構:

Linux Kernel UDP的部份的程式碼不多,所以極為容易了解大致的工作原理。
UDP的接收端大致工作模型分為四部份:
int udp_rcv(struct sk_buff *skb)
{
return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);
}
以上大致上可以知道,下一步的處理程式,兵分二路,其中 _udp4_lib_mcast_deliver() 處理Multicasting,其他的封包送到 udp_queue_rcv_skb () 來處理,規屬於UDPLITE 。
大致就這樣,所以 udp_mem 這個 BUFFER的SIZE,的確對於 INERRORS 會有影響。

Linux Kernel UDP的部份的程式碼不多,所以極為容易了解大致的工作原理。
UDP的接收端大致工作模型分為四部份:
- Link Layer (就是IP模組),接收封包之後,如果是本機要處理,就將封包送給UDP/TCP層來處理。
- 如果是UDP就呼叫Kernel UDP模組來處理。
- UDP模組對封包進行簡單的檢查,如果沒有問題,就把封包放到接收QUEUE當中。等待使用者模式的程式來處理。
- User Space程式呼叫read()或Socket等system call,讀取已經放入UDP Receive Queue。接收佇列中的資料。
下面的Trace基本上就是看步驟二是如何工作的?
udp_rcv() 是整個 UDP 模組的進入點。程式在 ./net/udp.c 當中。
這個Call函式是在AF_INET protocol init 的時候,由UDP註冊給 Network Layer 的Call Back 。
./net/af_inet.c
...
static const struct net_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.gso_send_check = udp4_ufo_send_check,
.gso_segment = udp4_ufo_fragment,
.no_policy = 1,
.netns_ok = 1,
};
...
網路層程式碼處理完一個輸入的資料封包後,如果該封包是發往本機的,並且其上層協議是UDP,那麼會呼叫這個被註冊的Call Back。
{
return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);
}
//
// All we need to do is get the socket, and then do a checksum.
// __udp4_lib_rcv() 這個程式幾乎就是整個UDP工作的中控,其他程式都是圍繞著這個程式來服務他。// 先看他的三個輸入:
// *skb : 就是由上層傳下來的封包。
// udp_table: 這個資料結構就是UDP要傳送給應用程式的BUFFER。由於等著要收封包的應用程式,不是一個,所以這是一個很大的Hash Table,UDP模組要分辨出,封包屬於哪一個應用程式,將封包放入這個應用程式的QUEUE。
// proto: 他有兩個L4 Protocol選項: IPPROTO_UDP 或 IPPROTO_UDPLITE
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable,
int proto)
{
struct sock *sk;
struct udphdr *uh;
unsigned short ulen;
struct rtable *rt = skb_rtable(skb);
__be32 saddr, daddr;
struct net *net = dev_net(skb->dev);
/*
* Validate the packet.
*/
// pskb_may_pull() 這程式很簡單,只是看一下送進來的封包,如果SIZE比UPD Header的SIZE還小,顯然是沒有用的封包,那就沒有處理的必要了。
// 這是一個inline function,位於 ./include/linux/skbuff.h 之中。
//
if (!pskb_may_pull(skb, sizeof(struct udphdr)))
goto drop; /* No space for header. */
// 把封包當中要用的參數拿出來
uh = udp_hdr(skb);
ulen = ntohs(uh->len);
// 取出封包的來源地址與目的地址
saddr = ip_hdr(skb)->saddr;
daddr = ip_hdr(skb)->daddr;
// skb中的資料長度不能小於UDP Header指示的資料包長度,如果太小就到短封包處理,如果大於,就是說封包之中是有資料的,需要繼續處理。
if (ulen > skb->len)
goto short_packet;
if (proto == IPPROTO_UDP) {
/* UDP validates ulen. */
// 這裡做了兩件事:
// UDP的資料長度必須大於HEADER。
// 由於IP模組對於不合理的UDP短封包,會填入一些垃圾資訊,所以 pskb_trim_rcsum()會處理掉垃圾資訊,重新計算CHECK SUM。
if (ulen < sizeof(*uh) || pskb_trim_rcsum(skb, ulen))
goto short_packet;
// 由於SIZE有可能改變,所以又重新指定了一次uh變數。
uh = udp_hdr(skb);
}
// 對封包做CHECK SUM檢查
if (udp4_csum_init(skb, uh, proto))
goto csum_error;
// 如果是Multcasting,在這裡就離開,做特殊的處理。
if (rt->rt_flags & (RTCF_BROADCAST|RTCF_MULTICAST))
return __udp4_lib_mcast_deliver(net, skb, uh,
saddr, daddr, udptable);
// 如果是一般封包,就要尋找應用程式QUEUE的位置,準備將資料往應用程式傳送
// 根據封包的 source port 和 object port 查詢 udptable,尋找應該接收該資料包的傳輸控制塊
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk != NULL) {
// 如果找到了,呼叫 udp_queue_rcv_skb (),將資料放入Queue當中
int ret = udp_queue_rcv_skb(sk, skb);
// Call sock_put, 如果 Queue 已經沒有東西 -> call sk_free()
sock_put(sk);
/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/
if (ret > 0)
return -ret;
return 0;
}
// 接下來,就要處理這些沒有要人要處理的封包。
// 先做一些 IPSec的規則檢查,做了甚麼,這裡沒有細看。
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
goto drop;
nf_reset(skb);
/* No socket. Drop packet silently, if checksum is wrong */
if (udp_lib_checksum_complete(skb))
goto csum_error;
//累計輸入資料包錯誤統計值,
UDP_INC_STATS_BH(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
// 回覆ICMP,這個PORT,封包無法送達
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
/*
* Hmm. We got an UDP packet to a port to which we
* don't wanna listen. Ignore it.
*/
// 與這些無法處理、送達的封包說再見。
kfree_skb(skb);
return 0;
short_packet:
// 短封包,就在LOG當中顯示一下訊息
LIMIT_NETDEBUG(KERN_DEBUG "UDP%s: short packet: From %pI4:%u %d/%d to %pI4:%u\n",
proto == IPPROTO_UDPLITE ? "-Lite" : "",
&saddr,
ntohs(uh->source),
ulen,
skb->len,
&daddr,
ntohs(uh->dest));
goto drop;
csum_error:
/*
* RFC1122: OK. Discards the bad packet silently (as far as
* the network is concerned, anyway) as per 4.1.3.4 (MUST).
*/
LIMIT_NETDEBUG(KERN_DEBUG "UDP%s: bad checksum. From %pI4:%u to %pI4:%u ulen %d\n",
proto == IPPROTO_UDPLITE ? "-Lite" : "",
&saddr,
ntohs(uh->source),
&daddr,
ntohs(uh->dest),
ulen);
drop:
// 在 /proc/net/ipv4/snmp 當中,紀錄UDPLITE的InErrors 加一
UDP_INC_STATS_BH(net, UDP_MIB_INERRORS, proto == IPPROTO_UDPLITE);
kfree_skb(skb);
return 0;
}
以上大致上可以知道,下一步的處理程式,兵分二路,其中 _udp4_lib_mcast_deliver() 處理Multicasting,其他的封包送到 udp_queue_rcv_skb () 來處理,規屬於UDPLITE 。
static int __udp4_lib_mcast_deliver(struct net *net, struct sk_buff *skb,
struct udphdr *uh,
__be32 saddr, __be32 daddr,
struct udp_table *udptable)
{
struct sock *sk, *stack[256/sizeof(struct sock *)];
struct udp_hslot *hslot = udp_hashslot(udptable, net, ntohs(uh->dest));
int dif;
unsigned int i, count = 0;
spin_lock(&hslot->lock);
sk = sk_nulls_head(&hslot->head);
dif = skb->dev->ifindex;
// Multicasting 的封包比較長,所以要一筆一筆處理到結束 sk = udp_v4_mcast_next(net, sk, uh->dest, daddr, uh->source, saddr, dif);
while (sk) { // 如果有需多封包,就一筆一筆放到STACK當中
stack[count++] = sk;// 放好之後,就讀下一筆來處理sk = udp_v4_mcast_next(net, sk_nulls_next(sk), uh->dest, daddr, uh->source, saddr, dif); // 如果STACK滿了封包還沒有結束,必須要離開迴圈。離開之前,還是要把Buffer處理到USER SPACE (Call flush_stack)
if (unlikely(count == ARRAY_SIZE(stack))) {
if (!sk)
break;
flush_stack(stack, count, skb, ~0);
count = 0;
}
}
/*
* before releasing chain lock, we must take a reference on sockets
*/
for (i = 0; i < count; i++)
sock_hold(stack[i]);
spin_unlock(&hslot->lock);
/*
* do the slow work with no lock held
*/
if (count) { // call flush_stack 把PACKET送到 SOCKET 去。
flush_stack(stack, count, skb, count - 1);
// 把stack的記憶體Free調
for (i = 0; i < count; i++)
sock_put(stack[i]);
} else {
kfree_skb(skb);
}
return 0;}
// 接下來看 flush_stack(),這就是將Stack中的資料,一筆筆COPY到 SOCKET BUFFER。
static void flush_stack(struct sock **stack, unsigned int count,
struct sk_buff *skb, unsigned int final)
{
unsigned int i;
struct sk_buff *skb1 = NULL;
struct sock *sk;
for (i = 0; i < count; i++) {
sk = stack[i];
if (likely(skb1 == NULL))
skb1 = (i == final) ? skb : skb_clone(skb, GFP_ATOMIC);
// 上面的skb_clone() 先依照 sk 的內容,建立一個資料結構。 // 如果 socket buffer 之中的記憶體已經用光,就做不下去了,於是紀錄一個Error。
if (!skb1) {
atomic_inc(&sk->sk_drops);
UDP_INC_STATS_BH(sock_net(sk), UDP_MIB_RCVBUFERRORS,
IS_UDPLITE(sk));
UDP_INC_STATS_BH(sock_net(sk), UDP_MIB_INERRORS, IS_UDPLITE(sk));
} // 如果可以拿到Buffer,就可以完成最終完成資料傳送的Call
if (skb1 && udp_queue_rcv_skb(sk, skb1) <= 0)
skb1 = NULL;
}
if (unlikely(skb1))
kfree_skb(skb1);
}
大致就這樣,所以 udp_mem 這個 BUFFER的SIZE,的確對於 INERRORS 會有影響。
2020年5月21日 星期四
Hermes神級Smart Speaker開箱
2019年高雄國際音響展,偶然遇到一家奇怪的公司在賣音響,這公司叫做Sound Machine,說是德國的牌子,但只有展示產品,但不賣東西。據說還在找代理商。
由於該公司的參展小姐實在太正,產品叫做Hermes,實在非常漂亮,所以留下了聯繫資料。前一陣子通知說,已經有代理商,約我去聽。視聽之後,就立刻入手了一台。
其實原先我看上的是白色的展示機,不過卻說是限量版,已經有人訂走了,只能買黑色的版本。
我原先使用的喇叭是BOSE的小喇吧,也花了15000大洋,但是連Bluetooth都沒有,只能用R/L (耳機孔),後來手機的耳機孔也取消了,想聽好一點的聲音還要用USB TYPE-C轉成耳機,真是麻煩死了。
雖然這機器主打的 Dolby ATMOS,但是我只是想用Bluetooth連一下手機,然後聽一下Youtube,這樣就是我日常的用法了。
當然電視機的AUDIO OUT 輸入也會接上,我用的ARC,Hermes可以支援到 eARC,但是我家電視機沒有支援(殘念)。
開箱後,就接上電,就迫不及待直接接上我的SONY手機。
2019年勉強出了第二張專輯,前面已經出了四條歌,都淹沒在歌海當中。誰知道Dua Lipa的新專輯連續推出三條主打歌都是Disco曲風。把這種復古的調調,炒得火熱。而"Say So"這首歌幾乎是百搭,於是一堆人裡用她的節奏做出一堆混音。後來就成了神曲。這便是開箱試播的第一條歌。
簡單說就是想先試一下Hermes的低音炮,到底有多威? 結果低音才一出來,就把木製的電視架幾乎轟垮,最後趕快跑到PCHOME買了一塊石英磚當墊子才解決。還來爬文,有人是墊了一塊大理石地磚,這樣比較美觀。
第一條歌播完,確認Hermes用來開趴絕無問題,豐沛到難以想像的重低音,完全與Hermes小小的身軀無法相對應。
第二條是播的歌曲是最近爆紅的三十年前日本老歌 Plastic Love。這歌曲的原唱是竹內瑪麗亞年輕時期的作品,她今年已經六十五歲了,活躍日本歌壇一輩子。Plastic Love根本就不是她的當年的主打歌。
2017年,一個叫做"Plastic Lover"的YouTuber把這首歌,貼上了他的網站。沒想到因為Google的推薦演算法把這首Urban Jazz風格的歌曲不斷出現在推薦歌單當中。難想像的這首老歌的風格在現今聽來,也沒有老派的感覺。於是在歐美傳唱起來。
我選播的歌曲不是原唱,而是一個剛走紅的日本新團Friday Night Plans。這是Live的錄音,四個團員以Bass, 鼓, 鍵盤與主唱的人聲,交織出完美的都會音樂風情。透過Hermes完美的音場定位,當我閉上眼睛,似乎演唱者就在我面前。
第三首歌曲試驗了一首中文歌曲,叫做"可惜了"。這是莫文蔚與齊秦的合唱,我常在車上聽這首歌。
這歌確實很好聽,一開始莫文蔚用High Key唱,齊秦用Low Key來唱合聲,剛好跟他們兩位的強項反過來,後來,齊秦恢復了唱漂亮的High Key之後,莫文蔚的聲音又被壓過去了。
但其實我用我的SONY監聽耳機來聽,男女生的錄音是均衡的。後來我用這首歌,試過一些喇叭,結果都是可惜了。
試聽結果呢? 我想Hermes 在兩人合唱的時候,很均勻的可以完整的清晰聽到齊秦與莫文蔚和聲。所以人聲的部份,通過了考驗。
第四首試聽的歌是"去年冬天"。這首歌有很厲害的故事,用動人的MV來呈現。
這個MV是五分鐘一鏡到底的拍法。男主角來自希臘,女主角是愛沙尼亞人。兩位都是跳舞的網紅。導演將佈景、歌曲先寄給他們編舞、在外國先練習好。
拍攝的前三天兩位舞者終於來到了台灣。到現場重新RE,依照實景做修正,大約排了三十多遍後就正式拍攝了。不得不說,這也許是我這輩子看過最厲害的中文MV了。
這個MV是五分鐘一鏡到底的拍法。男主角來自希臘,女主角是愛沙尼亞人。兩位都是跳舞的網紅。導演將佈景、歌曲先寄給他們編舞、在外國先練習好。
拍攝的前三天兩位舞者終於來到了台灣。到現場重新RE,依照實景做修正,大約排了三十多遍後就正式拍攝了。不得不說,這也許是我這輩子看過最厲害的中文MV了。
有多厲害,大家自己看就可以了。
回到音樂,歌曲用管樂開始,基本上,對了我胃口。接下來的鋼琴的段子,讓我雞皮疙瘩掉滿地。但是為何用他來測試喇叭呢? 主要是我用監聽耳機來聽這條歌的時候,他很密的鼓點與BASS有點混在一起,這是我想來用這首歌曲來測試HERMES的原因。
回到音樂,歌曲用管樂開始,基本上,對了我胃口。接下來的鋼琴的段子,讓我雞皮疙瘩掉滿地。但是為何用他來測試喇叭呢? 主要是我用監聽耳機來聽這條歌的時候,他很密的鼓點與BASS有點混在一起,這是我想來用這首歌曲來測試HERMES的原因。
就有點像第三條歌用了測試人聲。
結果呢? MV看來兩次,注意了都被這裡厲害的劇情給吸引走了,根本沒有辦法好好仔細聽這首歌。
結果呢? MV看來兩次,注意了都被這裡厲害的劇情給吸引走了,根本沒有辦法好好仔細聽這首歌。
2020年5月19日 星期二
Linux 系統 UDP 丟包問題分析
最近工作中,由於STB的VIDEO UDP 丟包,於開始一段對於Linux TCP/IP的複習。先用一張圖解釋 Linux 系統接收網路封包的過程:

首先網路封包會通過網路線-> PHY -> RGMII -> GEMAC。
網路驅動程式會把網路中的封包讀出來放到記憶體的 Ring Buffer 中,這個過程使用 DMA (Direct Memory Access),不需要 Main CPU 參與,Linux核心程式SoftIRQ從 Ring buffer 中讀取封包進行處理,執行 IP 和 TCP/UDP 層的邏輯,最後把封包放到應用程式的 Socket Buffer 中。
應用程式從 socket buffer 中讀取封包進行處理
在接收 UDP 封包的過程中,圖中任何一個過程都可能會主動或者被動地把封包丟棄,因此丟包可能發生在網卡和驅動,也可能發生在系統和應用。
之所以沒有分析發送資料流程程,一是因為發送流程和接收類似,只是方向相反;另外發送流程封包丟失的機會通常比接收小的多。
STB雖然用的GENET1,但是由於GENET0沒有啟動,所以依然是使用,eth0的interface。後面RX (receive)表示接收封包,TX(transmit)表示發送封包。
確認有 UDP 丟包發生的命令
要查看ETHENET MAC是否有丟包? TestApp下使用 ethtool -S eth0 查看,在輸出中查找 bad 或者 drop 對應的欄位是否有資料,在正常情況下,這些欄位對應的數字應該都是 0。如果看到對應的數字在不斷增長,就說明網卡有丟包。
而Client Build 之中沒有 ethtool, ifconfig 也是一樣的效果:
# ifconfig eth0
eth0 Link encap:Ethernet HWaddr AC:6F:BB:8B:2F:CA
inet addr:192.168.2.106 Bcast:192.168.2.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:94710232 errors:7580 dropped:7580 overruns:0 frame:0
TX packets:84125 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes: 852509147 (813.0 MiB) TX bytes:27528913 (26.2 MiB)
這裡可以RX看到掉了一些,計算之後,大約產生了0.0080%的掉包。那UDP的狀況呢? 因為沒有工具,所以只好到/proc之中去看看。
# cd /proc/net/
# /proc/5984/net # cat snmp | grep -i udp
Udp: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti
Udp: 94474880 383 111992 51512 111992 0 0 1151
UdpLite: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti
UdpLite: 0 0 0 0 0 0 0 0
這裡看到的數字就非常差了: 這裡的單位是Package,
InDatagrams 94,474,880 // 進來的UDP封包
NoPorts 383 //
InErrors 111992 // 進來的UDP封包 產生的Error
OutDatagrams 51512
RcvbufErrors 111992 // RcvbufErrors, 0.11% Error,這裡的掉包就是Buffer Size不足,這個數字與InErrors的值是一樣的
SndbufErrors 0
InCsumErrors 0
IgnoredMulti 1151 // 被忽略的Multicast 封包。
此外,TestApp可以使用 netstat -s 命令查看,加上 --udp 可以只看 UDP 相關的封包資料:
# netstat -s -u <Enter>
IcmpMsg:
InType0: 3
InType3: 1719356
InType8: 13
InType11: 59
OutType0: 13
OutType3: 1737641
OutType8: 10
OutType11: 263
Udp:
517488890 packets received
2487375 packets to unknown port received.
47533568 packet receive errors
147264581 packets sent
12851135 receive buffer errors
0 send buffer errors
UdpLite:
…
IpExt:
OutMcastPkts: 696
InBcastPkts: 2373968
InOctets: 4954097451540
OutOctets: 5538322535160
OutMcastOctets: 79632
InBcastOctets: 934783053
InNoECTPkts: 5584838675
對於上面的輸出,關注下面的資訊來查看 UDP 丟包的情況:
packet receive errors 不為 0 ,並且在一直增長,說明系統有 UDP 丟包。
packets to unknown port received 表示系統接收到的 UDP 封包所在的目標埠沒有應用在監聽,一般是服務沒有啟動導致的,並不會造成嚴重的問題。
receive buffer errors 表示因為 UDP 的接收Buufer太小導致丟包的數量。
並不是丟包數量不為零就有問題,對於 UDP 來說,如果有少量的丟包很可能是預期的行為,比如丟包率(丟包數量/接收封包數量)在萬分之一甚至更低。
網卡或者驅動程式丟包
之前講過,如果 ethtool -S eth0 中有 rx_***_errors 那麼很可能是實體網路有問題,導致系統丟包。
# ethtool -S eth0 | grep rx_ | grep errors
rx_crc_errors: 0
rx_missed_errors: 0
rx_long_length_errors: 0
rx_short_length_errors: 0
rx_align_errors: 0
rx_errors: 0
rx_length_errors: 0
rx_over_errors: 0
rx_frame_errors: 0
rx_fifo_errors: 0
netstat -i 也會提供每個網卡的接發封包以及丟包的情況,正常情況下輸出中 error 或者 drop 應該為 0。
如果硬體或者驅動沒有問題,一般網卡丟包是因為設置的緩存區(ring buffer)太小,可以使用 ethtool 命令查看和設置網卡的 ring buffer。
ethtool -g 可以查看某個網卡的 ring buffer,比如下面的例子
# ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
Pre-set 表示網卡最大的 ring buffer 值,可以使用 ethtool -G eth0 rx 8192 設置它的值。
Linux 系統丟包
Linux 系統丟包的原因很多,常見的有:UDP 封包錯誤、UDP buffer size 不足、系統負載過高等,這裡對這些丟包原因進行分析。
UDP 封包錯誤
如果在傳輸過程中UDP 封包被修改,會導致 checksum 錯誤,或者長度錯誤,Linux 在接收到 UDP 封包時會對此進行校驗,一旦發明錯誤會把封包丟棄。
如果希望 UDP 封包 checksum 及時有錯也要發送給應用程式,可以在通過 socket 參數關掉 UDP checksum 檢查:
int disable = 1;
setsockopt(sock_fd, SOL_SOCKET, SO_NO_CHECK, (void*)&disable, sizeof(disable)
UDP buffer size 不足
Linux 系統在接收封包之後,會把封包保存到緩存區中。因為緩存區的大小是有限的,如果出現 UDP 封包過大(超過緩存區大小或者 MTU 大小)、接收到封包的速率太快,都可能導致 Linux 因為緩存滿而直接丟包的情況。
在系統層面,Linux 設置了 receive buffer 可以配置的最大值,可以在下面的檔中查看,一般是 Linux 在啟動的時候會根據記憶體大小設置一個初始值。
/proc interfaces
System-wide UDP parameter settings can be accessed by files in the directory /proc/sys/net/ipv4/.
udp_mem: This is a vector of three integers governing the number of pages allowed for queueing by all UDP sockets.
min: Below this number of pages, UDP is not bothered about its memory appetite.
When the amount of memory allocated by UDP exceeds this number, UDP starts to moderate memory usage.
pressure: This value was introduced to follow the format of tcp_mem (see tcp(7)).
max: Number of pages allowed for queueing by all UDP sockets.
Defaults values for these three items are calculated at boot time from the amount of available memory.
udp_rmem_min (integer; default value: PAGE_SIZE;)
Minimal size, in bytes, of receive buffers used by UDP sockets in moderation.
Each UDP socket is able to use the size for receiving data, even if total pages of UDP sockets exceed udp_mem pressure.
udp_wmem_min (integer; default value: PAGE_SIZE;)
Minimal size, in bytes, of send buffer used by UDP sockets in moderation.
Each UDP socket is able to use the size for sending data, even if total pages of UDP sockets exceed udp_mem pressure.
/proc/sys/net/core/rmem_max: 允許設置的 receive buffer 最大值
/proc/sys/net/core/rmem_default:預設使用的 receive buffer 值
/proc/sys/net/core/wmem_max: 允許設置的 send buffer 最大值
/proc/sys/net/core/wmem_dafault:預設使用的 send buffer 最大值
在G5盒子上的值如下:
/proc/sys/net/core # cat rmem_max 2097512
/proc/sys/net/core # cat rmem_def* 163840
/proc/sys/net/core # cat netdev_budget 300
/proc/sys/net/core # cat netdev_max_backlog 1000
/proc/sys/net/ipv4 # cat udp_mem 8379 11175 16758
/proc/sys/net/ipv4 # cat udp_rmem_min 4096
/proc/sys/net/ipv4 # cat udp_wmem_min 4096
這時候回頭看了一下DT_G4的盒子:
/proc/1599/net # uptime
07:19:26 up 1:30, 0 users, load average: 0.37, 0.33, 0.28
/proc/1599/net # cat snmp | grep -i udp
Udp: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti
Udp: 1392551 161 0 3731 0 0 0 86
UdpLite: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti
UdpLite: 0 0 0 0 0 0 0 0
InError 都是 0。
/proc/1599/net # ifconfig eth0
eth0 Link encap:Ethernet HWaddr AC:6F:BB:57:18:DA
inet addr:192.168.2.111 Bcast:192.168.2.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1465386 errors:0 dropped:0 overruns:0 frame:0
TX packets:16647 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1993097447 (1.8 GiB) TX bytes:3483616 (3.3 MiB)
網卡也沒有掉包。於是檢查一下UDP Buffer的設定,有沒有差異?
唯一有差異的是 udp_mem。
/proc/sys/net/ipv4 # cat udp_mem
10029 13375 20058 // G4 DevBuild 的設定
/proc/sys/net/ipv4 # cat udp_mem
8379 11175 16758 // G5 DevBuild 的設定
G5 的Size 小了 20%。又看了 一下TestApp
G4 : 11640 11520 23280
G5: 10626 14168 21252
都不一樣。
如何調大一些呢?
# echo "1640 11520 23280" > udp_mem <Enter>
可以使用 sysctl 命令讓它立即生效:
sysctl -w net.core.rmem_max=1024000
sysctl -w net.core.wmem_max=1024000
sysctl -w net.core.wmem_default=1024000
sysctl -w net.core.rmem_default=1024000
sysctl -w net.ipv4.udp_mem="1024000 1024000 1024000"
sysctl -w net.ipv4.udp_rmem_min=1024000
sysctl -w net.ipv4.udp_wmem_min=1024000
設定後,可以查詢
# sysctl -a
# sysctl -w net.core.rmem_max=26214400 # 設定BUFFER為 25M
也可以修改 /etc/sysctl.conf 中對應的參數在下次啟動時讓參數保持生效。
如果封包封包過大,可以在發送方對資料進行分割,保證每個封包的大小在 MTU 內。
另外一個可以配置的參數是 netdev_max_backlog,它表示 Linux 核心程式從網卡驅動中讀取封包後可以BUFFER的封包數量,預設是 1000,可以調大這個值,比如設置成 2000:
# sysctl -w net.core.netdev_max_backlog=2000
系統負載過高
系統 CPU、memory、IO 負載過高都有可能導致網路丟包,比如 CPU 如果負載過高,系統沒有時間進行封包的 checksum 計算、複製記憶體等操作,從而導致網卡或者 socket buffer 出丟包;memory 負載過高,會應用程式處理過慢,無法及時處理封包;IO 負載過高,CPU 都用來回應 IO wait,沒有時間處理緩存中的 UDP 封包。
Linux 系統本身就是相互關聯的系統,任何一個元件出現問題都有可能影響到其他元件的正常運行。對於系統負載過高,要麼是應用程式有問題,要麼是系統不足。對於前者需要及時發現,debug 和修復;對於後者,也要及時發現並擴容。
應用丟包
上面提到系統的 UDP buffer size,調節的 sysctl 參數只是系統允許的最大值,每個應用程式在創建 socket 時需要設置自己 socket buffer size 的值。
Linux 系統會把接受到的封包放到 socket 的 buffer 中,應用程式從 buffer 中不斷地讀取封包。所以這裡有兩個和應用有關的因素會影響是否會丟包:socket buffer size 大小以及應用程式讀取封包的速度。
對於第一個問題,可以在應用程式初始化 socket 的時候設置 socket receive buffer 的大小,比如下面的代碼把 socket buffer 設置為 20MB:
uint64_t receive_buf_size = 20*1024*1024; //20 MB
setsockopt(socket_fd, SOL_SOCKET, SO_RCVBUF, &receive_buf_size, sizeof(receive_buf_size));
很明顯,增加應用的 receive buffer 會減少丟包的可能性。另外一個因素是應用讀取 buffer 中封包的速度,對於應用程式來說,處理封包應該採取非同步的方式
包丟在什麼地方??
想要詳細瞭解 Linux 系統在執行哪個函數時丟包的話,可以使用 dropwatch 工具,它監聽系統丟包資訊,目前的Kernel當中,已經有加入 kfree_skb()的資訊,並列印出丟包發生的函數位址:
# dropwatch -l kas
Initalizing kallsyms db
dropwatch> start
Enabling monitoring...
Kernel monitoring activated.
Issue Ctrl-C to stop monitoring
1 drops at tcp_v4_do_rcv+cd (0xffffffff81799bad)
10 drops at tcp_v4_rcv+80 (0xffffffff8179a620)
1 drops at sk_stream_kill_queues+57 (0xffffffff81729ca7)
4 drops at unix_release_sock+20e (0xffffffff817dc94e)
1 drops at igmp_rcv+e1 (0xffffffff817b4c41)
1 drops at igmp_rcv+e1 (0xffffffff817b4c41)
通過這些資訊,找到對應的核心程式代碼處,就能知道核心程式在哪個步驟中把封包丟棄,以及大致的丟包原因。可惜目前的系統之中,沒有加入這個命令。
此外,還可以使用 Linux perf 工具也可以監聽 kfree_skb()(把網路封包丟棄時會調用該函數) 使用方式:
# perf record -g -a -e skb:kfree_skb
# perf script
關於 perf 命令的使用和解讀,網上有很多文章可以參考。
首先網路封包會通過網路線-> PHY -> RGMII -> GEMAC。
網路驅動程式會把網路中的封包讀出來放到記憶體的 Ring Buffer 中,這個過程使用 DMA (Direct Memory Access),不需要 Main CPU 參與,Linux核心程式SoftIRQ從 Ring buffer 中讀取封包進行處理,執行 IP 和 TCP/UDP 層的邏輯,最後把封包放到應用程式的 Socket Buffer 中。
應用程式從 socket buffer 中讀取封包進行處理
在接收 UDP 封包的過程中,圖中任何一個過程都可能會主動或者被動地把封包丟棄,因此丟包可能發生在網卡和驅動,也可能發生在系統和應用。
之所以沒有分析發送資料流程程,一是因為發送流程和接收類似,只是方向相反;另外發送流程封包丟失的機會通常比接收小的多。
STB雖然用的GENET1,但是由於GENET0沒有啟動,所以依然是使用,eth0的interface。後面RX (receive)表示接收封包,TX(transmit)表示發送封包。
確認有 UDP 丟包發生的命令
要查看ETHENET MAC是否有丟包? TestApp下使用 ethtool -S eth0 查看,在輸出中查找 bad 或者 drop 對應的欄位是否有資料,在正常情況下,這些欄位對應的數字應該都是 0。如果看到對應的數字在不斷增長,就說明網卡有丟包。
而Client Build 之中沒有 ethtool, ifconfig 也是一樣的效果:
# ifconfig eth0
eth0 Link encap:Ethernet HWaddr AC:6F:BB:8B:2F:CA
inet addr:192.168.2.106 Bcast:192.168.2.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:94710232 errors:7580 dropped:7580 overruns:0 frame:0
TX packets:84125 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes: 852509147 (813.0 MiB) TX bytes:27528913 (26.2 MiB)
這裡可以RX看到掉了一些,計算之後,大約產生了0.0080%的掉包。那UDP的狀況呢? 因為沒有工具,所以只好到/proc之中去看看。
# cd /proc/net/
# /proc/5984/net # cat snmp | grep -i udp
Udp: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti
Udp: 94474880 383 111992 51512 111992 0 0 1151
UdpLite: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti
UdpLite: 0 0 0 0 0 0 0 0
這裡看到的數字就非常差了: 這裡的單位是Package,
InDatagrams 94,474,880 // 進來的UDP封包
NoPorts 383 //
InErrors 111992 // 進來的UDP封包 產生的Error
OutDatagrams 51512
RcvbufErrors 111992 // RcvbufErrors, 0.11% Error,這裡的掉包就是Buffer Size不足,這個數字與InErrors的值是一樣的
SndbufErrors 0
InCsumErrors 0
IgnoredMulti 1151 // 被忽略的Multicast 封包。
此外,TestApp可以使用 netstat -s 命令查看,加上 --udp 可以只看 UDP 相關的封包資料:
# netstat -s -u <Enter>
IcmpMsg:
InType0: 3
InType3: 1719356
InType8: 13
InType11: 59
OutType0: 13
OutType3: 1737641
OutType8: 10
OutType11: 263
Udp:
517488890 packets received
2487375 packets to unknown port received.
47533568 packet receive errors
147264581 packets sent
12851135 receive buffer errors
0 send buffer errors
UdpLite:
…
IpExt:
OutMcastPkts: 696
InBcastPkts: 2373968
InOctets: 4954097451540
OutOctets: 5538322535160
OutMcastOctets: 79632
InBcastOctets: 934783053
InNoECTPkts: 5584838675
對於上面的輸出,關注下面的資訊來查看 UDP 丟包的情況:
packet receive errors 不為 0 ,並且在一直增長,說明系統有 UDP 丟包。
packets to unknown port received 表示系統接收到的 UDP 封包所在的目標埠沒有應用在監聽,一般是服務沒有啟動導致的,並不會造成嚴重的問題。
receive buffer errors 表示因為 UDP 的接收Buufer太小導致丟包的數量。
並不是丟包數量不為零就有問題,對於 UDP 來說,如果有少量的丟包很可能是預期的行為,比如丟包率(丟包數量/接收封包數量)在萬分之一甚至更低。
網卡或者驅動程式丟包
之前講過,如果 ethtool -S eth0 中有 rx_***_errors 那麼很可能是實體網路有問題,導致系統丟包。
# ethtool -S eth0 | grep rx_ | grep errors
rx_crc_errors: 0
rx_missed_errors: 0
rx_long_length_errors: 0
rx_short_length_errors: 0
rx_align_errors: 0
rx_errors: 0
rx_length_errors: 0
rx_over_errors: 0
rx_frame_errors: 0
rx_fifo_errors: 0
netstat -i 也會提供每個網卡的接發封包以及丟包的情況,正常情況下輸出中 error 或者 drop 應該為 0。
如果硬體或者驅動沒有問題,一般網卡丟包是因為設置的緩存區(ring buffer)太小,可以使用 ethtool 命令查看和設置網卡的 ring buffer。
ethtool -g 可以查看某個網卡的 ring buffer,比如下面的例子
# ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
Pre-set 表示網卡最大的 ring buffer 值,可以使用 ethtool -G eth0 rx 8192 設置它的值。
Linux 系統丟包
Linux 系統丟包的原因很多,常見的有:UDP 封包錯誤、UDP buffer size 不足、系統負載過高等,這裡對這些丟包原因進行分析。
UDP 封包錯誤
如果在傳輸過程中UDP 封包被修改,會導致 checksum 錯誤,或者長度錯誤,Linux 在接收到 UDP 封包時會對此進行校驗,一旦發明錯誤會把封包丟棄。
如果希望 UDP 封包 checksum 及時有錯也要發送給應用程式,可以在通過 socket 參數關掉 UDP checksum 檢查:
int disable = 1;
setsockopt(sock_fd, SOL_SOCKET, SO_NO_CHECK, (void*)&disable, sizeof(disable)
UDP buffer size 不足
Linux 系統在接收封包之後,會把封包保存到緩存區中。因為緩存區的大小是有限的,如果出現 UDP 封包過大(超過緩存區大小或者 MTU 大小)、接收到封包的速率太快,都可能導致 Linux 因為緩存滿而直接丟包的情況。
在系統層面,Linux 設置了 receive buffer 可以配置的最大值,可以在下面的檔中查看,一般是 Linux 在啟動的時候會根據記憶體大小設置一個初始值。
/proc interfaces
System-wide UDP parameter settings can be accessed by files in the directory /proc/sys/net/ipv4/.
udp_mem: This is a vector of three integers governing the number of pages allowed for queueing by all UDP sockets.
min: Below this number of pages, UDP is not bothered about its memory appetite.
When the amount of memory allocated by UDP exceeds this number, UDP starts to moderate memory usage.
pressure: This value was introduced to follow the format of tcp_mem (see tcp(7)).
max: Number of pages allowed for queueing by all UDP sockets.
Defaults values for these three items are calculated at boot time from the amount of available memory.
udp_rmem_min (integer; default value: PAGE_SIZE;)
Minimal size, in bytes, of receive buffers used by UDP sockets in moderation.
Each UDP socket is able to use the size for receiving data, even if total pages of UDP sockets exceed udp_mem pressure.
udp_wmem_min (integer; default value: PAGE_SIZE;)
Minimal size, in bytes, of send buffer used by UDP sockets in moderation.
Each UDP socket is able to use the size for sending data, even if total pages of UDP sockets exceed udp_mem pressure.
/proc/sys/net/core/rmem_max: 允許設置的 receive buffer 最大值
/proc/sys/net/core/rmem_default:預設使用的 receive buffer 值
/proc/sys/net/core/wmem_max: 允許設置的 send buffer 最大值
/proc/sys/net/core/wmem_dafault:預設使用的 send buffer 最大值
在G5盒子上的值如下:
/proc/sys/net/core # cat rmem_max 2097512
/proc/sys/net/core # cat rmem_def* 163840
/proc/sys/net/core # cat netdev_budget 300
/proc/sys/net/core # cat netdev_max_backlog 1000
/proc/sys/net/ipv4 # cat udp_mem 8379 11175 16758
/proc/sys/net/ipv4 # cat udp_rmem_min 4096
/proc/sys/net/ipv4 # cat udp_wmem_min 4096
這時候回頭看了一下DT_G4的盒子:
/proc/1599/net # uptime
07:19:26 up 1:30, 0 users, load average: 0.37, 0.33, 0.28
/proc/1599/net # cat snmp | grep -i udp
Udp: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti
Udp: 1392551 161 0 3731 0 0 0 86
UdpLite: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti
UdpLite: 0 0 0 0 0 0 0 0
InError 都是 0。
/proc/1599/net # ifconfig eth0
eth0 Link encap:Ethernet HWaddr AC:6F:BB:57:18:DA
inet addr:192.168.2.111 Bcast:192.168.2.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1465386 errors:0 dropped:0 overruns:0 frame:0
TX packets:16647 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1993097447 (1.8 GiB) TX bytes:3483616 (3.3 MiB)
網卡也沒有掉包。於是檢查一下UDP Buffer的設定,有沒有差異?
唯一有差異的是 udp_mem。
/proc/sys/net/ipv4 # cat udp_mem
10029 13375 20058 // G4 DevBuild 的設定
/proc/sys/net/ipv4 # cat udp_mem
8379 11175 16758 // G5 DevBuild 的設定
G5 的Size 小了 20%。又看了 一下TestApp
G4 : 11640 11520 23280
G5: 10626 14168 21252
都不一樣。
如何調大一些呢?
# echo "1640 11520 23280" > udp_mem <Enter>
可以使用 sysctl 命令讓它立即生效:
sysctl -w net.core.rmem_max=1024000
sysctl -w net.core.wmem_max=1024000
sysctl -w net.core.wmem_default=1024000
sysctl -w net.core.rmem_default=1024000
sysctl -w net.ipv4.udp_mem="1024000 1024000 1024000"
sysctl -w net.ipv4.udp_rmem_min=1024000
sysctl -w net.ipv4.udp_wmem_min=1024000
設定後,可以查詢
# sysctl -a
# sysctl -w net.core.rmem_max=26214400 # 設定BUFFER為 25M
也可以修改 /etc/sysctl.conf 中對應的參數在下次啟動時讓參數保持生效。
如果封包封包過大,可以在發送方對資料進行分割,保證每個封包的大小在 MTU 內。
另外一個可以配置的參數是 netdev_max_backlog,它表示 Linux 核心程式從網卡驅動中讀取封包後可以BUFFER的封包數量,預設是 1000,可以調大這個值,比如設置成 2000:
# sysctl -w net.core.netdev_max_backlog=2000
系統負載過高
系統 CPU、memory、IO 負載過高都有可能導致網路丟包,比如 CPU 如果負載過高,系統沒有時間進行封包的 checksum 計算、複製記憶體等操作,從而導致網卡或者 socket buffer 出丟包;memory 負載過高,會應用程式處理過慢,無法及時處理封包;IO 負載過高,CPU 都用來回應 IO wait,沒有時間處理緩存中的 UDP 封包。
Linux 系統本身就是相互關聯的系統,任何一個元件出現問題都有可能影響到其他元件的正常運行。對於系統負載過高,要麼是應用程式有問題,要麼是系統不足。對於前者需要及時發現,debug 和修復;對於後者,也要及時發現並擴容。
應用丟包
上面提到系統的 UDP buffer size,調節的 sysctl 參數只是系統允許的最大值,每個應用程式在創建 socket 時需要設置自己 socket buffer size 的值。
Linux 系統會把接受到的封包放到 socket 的 buffer 中,應用程式從 buffer 中不斷地讀取封包。所以這裡有兩個和應用有關的因素會影響是否會丟包:socket buffer size 大小以及應用程式讀取封包的速度。
對於第一個問題,可以在應用程式初始化 socket 的時候設置 socket receive buffer 的大小,比如下面的代碼把 socket buffer 設置為 20MB:
uint64_t receive_buf_size = 20*1024*1024; //20 MB
setsockopt(socket_fd, SOL_SOCKET, SO_RCVBUF, &receive_buf_size, sizeof(receive_buf_size));
很明顯,增加應用的 receive buffer 會減少丟包的可能性。另外一個因素是應用讀取 buffer 中封包的速度,對於應用程式來說,處理封包應該採取非同步的方式
包丟在什麼地方??
想要詳細瞭解 Linux 系統在執行哪個函數時丟包的話,可以使用 dropwatch 工具,它監聽系統丟包資訊,目前的Kernel當中,已經有加入 kfree_skb()的資訊,並列印出丟包發生的函數位址:
# dropwatch -l kas
Initalizing kallsyms db
dropwatch> start
Enabling monitoring...
Kernel monitoring activated.
Issue Ctrl-C to stop monitoring
1 drops at tcp_v4_do_rcv+cd (0xffffffff81799bad)
10 drops at tcp_v4_rcv+80 (0xffffffff8179a620)
1 drops at sk_stream_kill_queues+57 (0xffffffff81729ca7)
4 drops at unix_release_sock+20e (0xffffffff817dc94e)
1 drops at igmp_rcv+e1 (0xffffffff817b4c41)
1 drops at igmp_rcv+e1 (0xffffffff817b4c41)
通過這些資訊,找到對應的核心程式代碼處,就能知道核心程式在哪個步驟中把封包丟棄,以及大致的丟包原因。可惜目前的系統之中,沒有加入這個命令。
此外,還可以使用 Linux perf 工具也可以監聽 kfree_skb()(把網路封包丟棄時會調用該函數) 使用方式:
# perf record -g -a -e skb:kfree_skb
# perf script
關於 perf 命令的使用和解讀,網上有很多文章可以參考。
2020年5月13日 星期三
netfilter framework study
netfilter框架
netfilter是linux內核中的一個數據包處理框架,用於替代原有的ipfwadm和ipchains等數據包處理程序。netfilter的功能包括數據包過濾,修改,SNAT/DNAT等。netfilter在內核協議棧的不同位置實現了5個hook點,其它內核模塊(比如ip_tables)可以向這些hook點註冊處理函數,這樣當數據包經過這些hook點時,其上註冊的處理函數就被依次調用,用戶層工具像iptables一般都需要相應內核模塊ip_tables配合以完成與netfilter的交互。netfilter hooks、ip{6}_tables、connection tracking、和NAT子系統一起構成了netfilter框架的主要部分。可以參考Netfilter Architecture了解更多內容
下面這張圖來自維基百科netfilter,它展示了netfilter框架在協議棧的位置,你們可能發現這張圖在我的博客中出現多次了,那是因為這張圖太經典了。它可以清楚地看到netfilter框架是如何處理通過不同協議棧路徑上的數據包
網絡過濾器
我們知道iptables的定位是IPv4 packet filter,它只處理IP數據包,而ebtables只工作在鏈路層Link Layer處理的是以太網幀(比如修改源目mac地址)。圖中用有顏色的長方形方框表示iptables或ebtables的表和鏈,綠色小方框表示network level,即iptables的表和鏈。藍色小方框表示bridge level,即ebtables的表和鏈,由於處理以太網幀相對簡單,因此鏈路層的藍色小方框相對較少。
我們還注意到一些代表iptables表和鏈的綠色小方框位於鏈路層,這是因為bridge_nf代碼的作用(從2.6 kernel開始),bridge_nf的引入是為了解決在鏈路層Bridge中處理IP數據包的問題(需要通過內核參數開啟),那為什麼要在鏈路層Bridge中處理IP數據包,而不等數據包通過網絡層時候再處理呢,這是因為不是所有的數據包都一定會通過網絡層,比如外部機器與主機上虛擬機的通信流量,bridge_nf也是openstack中實現安全組功能的基礎。
bridge_nf代碼有時候會引起困惑,就像我們在圖中看到的那樣,代表iptables表和鏈的綠色小方框跑到了鏈路層,netfilter文檔對此也有說明ebtables/iptables interaction on a Linux-based bridge
應當指出,br-nf代碼有時會違反TCP / IP網絡模型。稍後將看到,例如,有可能在鏈路層內部進行IP DNAT
ok,圖中長方形小方框已經解釋清楚了,還有一種橢圓形的方框conntrack,即connection tracking,這是netfilter提供的連接跟踪機制,此機制允許內核”審查”通過此處的所有網絡數據包,並能識別出此數據包屬於哪個網絡連接(比如數據包a屬於IP1:8888->IP2:80這個tcp連接,數據包b屬於ip3:9999->IP4:53這個udp連接)。因此,連接跟踪機制使內核能夠跟踪並記錄通過此處的所有網絡連接及其狀態。圖中可以清楚看到連接跟踪代碼所處的網絡棧位置,如果不想讓某些數據包被跟踪( NOTRACK),那就要找位於橢圓形方框conntrack之前的表和鏈來設置規則。conntrack機制是iptables實現狀態匹配( -m state)以及NAT的基礎,它由單獨的內核模塊nf_conntrack實現。下面還會詳細介紹
接著看圖中左下方bridge check方框,數據包從主機上的某個網絡接口進入( ingress),在bridge check處會檢查此網絡接口是否屬於某個Bridge的port,如果是就會進入Bridge代碼處理邏輯(下方藍色區域bridge level),否則就會送入網絡層Network Layer處理
圖中下方中間位置的bridging decision類似普通二層交換機的查表轉發功能,根據數據包目的MAC地址判斷此數據包是轉發還是交給上層處理,具體可以參考我另一篇文章linux-bridge
圖中中心位置的routing decision就是路由選擇,根據系統路由表( ip route查看),決定數據包是forward,還是交給本地處理
總的來看,不同packet有不同的packet flow,packet總是從主機的某個接口進入(左下方ingress),然後經過check/decision/一系列表和鏈處理,最後,目的地或是主機上某應用進程(上中位置local process),或是需要從主機另一個接口發出(右下方egress)。這裡的接口即可以是物理網卡em1,也可以是虛擬網卡tun0/vnetx,還可以是Bridge上的一個port。
上面就是關於這張圖的一些解釋,如果還有其它疑問,歡迎留言討論,下面說說netfilter框架的各個部分
連接跟踪
當加載內核模塊nf_conntrack後,conntrack機制就開始工作,如上圖,橢圓形方框conntrack在內核中有兩處位置(PREROUTING和OUTPUT之前)能夠跟踪數據包。對於每個通過conntrack的數據包,內核都為其生成一個conntrack條目用以跟踪此連接,對於後續通過的數據包,內核會判斷若此數據包屬於一個已有的連接,則更新所對應的conntrack條目的狀態(比如更新為ESTABLISHED狀態),否則內核會為它新建一個conntrack條目。所有的conntrack條目都存放在一張表裡,稱為連接跟踪表
那麼內核如何判斷一個數據包是否屬於一個已有的連接呢,我們先來了解下連接跟踪表
連接跟踪表
連接跟踪表存放於系統內存中,可以用cat /proc/net/nf_conntrack查看當前跟踪的所有conntrack條目。如下是代表一個tcp連接的conntrack條目,根據連接協議不同,下面顯示的字段信息也不一樣,比如icmp協議
ipv4 2 tcp 6 431955已建立src = 172.16.207.231 dst = 172.16.207.232 sport = 51071 dport = 5672 src = 172.16.207.232 dst = 172.16.207.231 sport = 5672 dport = 51071 [確定] mark = 0區域= use = 2
每個conntrack條目表示一個連接,連接協議可以是tcp,udp,icmp等,它包含了數據包的原始方向信息(藍色)和期望的響應包信息(紅色),這樣內核能夠在後續到來的數據包中識別出屬於此連接的雙向數據包,並更新此連接的狀態,各字段意思的具體分析後面會說。連接跟踪表中能夠存放的conntrack條目的最大值,即係統允許的最大連接跟踪數記作CONNTRACK_MAX
netfilter_hash_table
在內核中,連接跟踪表是一個二維數組結構的哈希表(hash table),哈希表的大小記作HASHSIZE,哈希表的每一項(hash table entry)稱作bucket,因此哈希表中有HASHSIZE個bucket存在,每個bucket包含一個鍊錶(linked list),每個鍊錶能夠存放若干個conntrack條目( bucket size)。對於一個新收到的數據包,內核使用如下步驟判斷其是否屬於一個已有連接:
內核提取此數據包信息(源目IP,port,協議號)進行hash計算得到一個hash值,在哈希表中以此hash值做索引,索引結果為數據包所屬的bucket(鍊錶)。這一步hash計算時間固定並且很短
遍歷hash得到的bucket,查找是否有匹配的conntrack條目。這一步是比較耗時的操作,bucket size越大,遍歷時間越長
如何設置最大連接跟踪數
根據上面對哈希表的解釋,系統最大允許連接跟踪數CONNTRACK_MAX= 连接跟踪表大小(HASHSIZE) * Bucket大小(bucket size)。從連接跟踪表獲取bucket是hash操作時間很短,而遍歷bucket相對費時,因此為了conntrack性能考慮,bucket size越小越好,默認為8
#查看系统当前最大连接跟踪数CONNTRACK_MAX
sysctl -a | grep net.netfilter.nf_conntrack_max
#net.netfilter.nf_conntrack_max = 3203072
#查看当前连接跟踪表大小HASHSIZE
sysctl -a | grep net.netfilter.nf_conntrack_buckets
#400384
#或者这样
cat /sys/module/nf_conntrack/parameters/hashsize
#400384
這兩個的比值即為bucket size = 3203072 / 400384
如下,現在需求是設置系統最大連接跟踪數為320w,由於bucket size不能直接設置,為了使bucket size值為8,我們需要同時設置CONNTRACK_MAX和HASHSIZE,因為他們的比值就是bucket size
#HASHSIZE (内核会自动格式化为最接近允许值)
echo 400000 > /sys/module/nf_conntrack/parameters/hashsize
#系统最大连接跟踪数
sysctl -w net.netfilter.nf_conntrack_max=3200000
#注意nf_conntrack内核模块需要加载
為了使nf_conntrack模塊重新加載或系統重啟後生效
#nf_conntrack模块提供了设置HASHSIZE的参数
echo "options nf_conntrack hashsize=400000" > /etc/modprobe.d/nf_conntrack.conf
只需要固化HASHSIZE值,nf_conntrack模塊在重新加載時會自動設置CONNTRACK_MAX = hashsize * 8,當然前提是你bucket size使用系統默認值8。如果自定義bucket size值,就需要同時固化CONNTRACK_MAX,以保持其比值為你想要的bucket size
上面我們沒有改變bucket size的默認值8,但是若內存足夠並且性能很重要,你可以考慮每個bucket一個conntrack條目( bucket size= 1),最大可能降低遍歷耗時,即HASHSIZE = CONNTRACK_MAX
#HASHSIZE
echo 3200000 > /sys/module/nf_conntrack/parameters/hashsize
#CONNTRACK_MAX
sysctl -w net.netfilter.nf_conntrack_max=3200000
如何計算連接跟踪所佔內存
連接跟踪表存儲在系統內存中,因此需要考慮內存佔用問題,可以用下面公式計算設置不同的最大連接跟踪數所佔最大系統內存
total_mem_used(bytes) = CONNTRACK_MAX * sizeof(struct ip_conntrack) + HASHSIZE * sizeof(struct list_head)
例如我們需要設置最大連接跟踪數為320w,在centos6/7系統上,sizeof(struct ip_conntrack)= 376,sizeof(struct list_head)= 16,並且bucket size使用默認值8,並且HASHSIZE = CONNTRACK_MAX / 8,因此
total_mem_used(bytes) = 3200000 * 376 + (3200000 / 8) * 16
# = 1153MB ~= 1GB
因此可以得到,在centos6/7系統上,設置320w的最大連接跟踪數,所消耗的內存大約為1GB,對現代服務器來說,佔用內存並不多,但conntrack實在讓人又愛又恨
關於上面兩個sizeof(struct *)值在你係統上的大小,如果會C就好說,如果不會,可以使用如下python代碼計算
import ctypes
#不同系统可能此库名不一样,需要修改
LIBNETFILTER_CONNTRACK = 'libnetfilter_conntrack.so.3.6.0'
nfct = ctypes.CDLL(LIBNETFILTER_CONNTRACK)
print 'sizeof(struct nf_conntrack):', nfct.nfct_maxsize()
print 'sizeof(struct list_head):', ctypes.sizeof(ctypes.c_void_p) * 2
conntrack條目
conntrack從經過它的數據包中提取詳細的,唯一的信息,因此能保持對每一個連接的跟踪。關於conntrack如何確定一個連接,對於tcp/udp,連接由他們的源目地址,源目端口唯一確定。對於icmp,由type,code和id字段確定。
ipv4 2 tcp 6 33 SYN_SENT src=172.16.200.119 dst=172.16.202.12 sport=54786 dport=10051 [UNREPLIED] src=172.16.202.12 dst=172.16.200.119 sport=10051 dport=54786 mark=0 zone=0 use=2
如上是一條conntrack條目,它代表當前已跟踪到的某個連接,conntrack維護的所有信息都包含在這個條目中,通過它就可以知道某個連接處於什麼狀態
此連接使用ipv4協議,是一條tcp連接(tcp的協議類型代碼是6)
33是這條conntrack條目在當前時間點的生存時間(每個conntrack條目都會有生存時間,從設置值開始倒計時,倒計時完後此條目將被清除),可以使用sysctl -a |grep conntrack | grep timeout查看不同協議不同狀態下生存時間設置值,當然這些設置值都可以調整,注意若後續有收到屬於此連接的數據包,則此生存時間將被重置(重新從設置值開始倒計時),並且狀態改變,生存時間設置值也會響應改為新狀態的值
SYN_SENT是到此刻為止conntrack跟踪到的這個連接的狀態(內核角度),SYN_SENT表示這個連接只在一個方向發送了一初始TCP SYN包,還未看到響應的SYN+ACK包(只有tcp才會有這個字段)。
src=172.16.200.119 dst=172.16.202.12 sport=54786 dport=10051是從數據包中提取的此連接的源目地址、源目端口,是conntrack首次看到此數據包時候的信息。
[UNREPLIED]說明此刻為止這個連接還沒有收到任何響應,當一個連接已收到響應時,[UNREPLIED]標誌就會被移除
接下來的src=172.16.202.12 dst=172.16.200.119 sport=10051 dport=54786地址和端口和前面是相反的,這部分不是數據包中帶有的信息,是conntrack填充的信息,代表conntrack希望收到的響應包信息。意思是若後續conntrack跟踪到某個數據包信息與此部分匹配,則此數據包就是此連接的響應數據包。注意這部分確定了conntrack如何判斷響應包(tcp/udp),icmp是依據另外幾個字段
上面是tcp連接的條目,而udp和icmp沒有連接建立和關閉過程,因此條目字段會有所不同,後面iptables狀態匹配部分我們會看到處於各個狀態的conntrack條目
注意conntrack機制並不能夠修改或過濾數據包,它只是跟踪網絡連接並維護連接跟踪表,以提供給iptables做狀態匹配使用,也就是說,如果你iptables中用不到狀態匹配,那就沒必要啟用conntrack
iptables狀態匹配
本部分參考自iptables文檔iptables-tutorial#The state machine,我找不到比它更全面的文章了
先明確下conntrack在內核協議棧所處位置,上面也提過conntrack跟踪數據包的位置在PREROUTING和OUTPUT這兩個hook點,主機自身進程產生的數據包會通過OUTPUT處的conntrack,從主機任意接口進入(包括Bridge的port)的數據包會通過PREROUTING處的conntrack,從netfilter框架圖上可以看到conntrack位置很靠前,僅在iptables的raw表之後,raw表主要作用就是允許我們對某些特定的數據包打上NOTRACK標記,這樣後面的conntrack就不會記錄此類帶有NOTRACK標籤的數據包。conntrack位置很靠前一方面是保證其後面的iptables表和鏈都能使用狀態匹配,另一方面使得conntrack能夠跟踪到任何進出主機的原始數據包(比如數據包還未NAT/FORWARD)。
iptables狀態匹配模塊
iptables狀態
iptables是帶有狀態匹配的防火牆,它使用-m state模塊從連接跟踪表查找數據包狀態。上面我們分析的那條conntrack條目處於SYN_SENT狀態,這是內核記錄的狀態,數據包在內核中可能會有幾種不同的狀態,但是映射到用戶空間iptables,只有5種狀態可用:NEW,ESTABLISHED,RELATED ,INVALID和UNTRACKED。注意這裡說的狀態不是tcp/ip協議中tcp連接的各種狀態。下面表格說明了這5種狀態分別能夠匹配什麼樣的數據包,注意下面兩點
用戶空間這5種狀態是iptables用於完成狀態匹配而定義的,不關聯與特定連接協議
conntrack記錄在前,iptables匹配在後(見netfilter框架圖)
狀態 解釋
新 NEW匹配連接的第一個包。意思就是,iptables從連接跟踪表中查到此包是某連接的第一個包。判斷此包是某連接的第一個包是依據conntrack當前”只看到一個方向數據包”( [UNREPLIED]),不關聯特定協議,因此NEW並不單指tcp連接的SYN包
已建立 ESTABLISHED匹配連接的響應包及後續的包。意思是,iptables從連接跟踪表中查到此包是屬於一個已經收到響應的連接(即沒有[UNREPLIED]字段)。因此在iptables狀態中,只要發送並接到響應,連接就認為是ESTABLISHED的了。這個特點使iptables可以控制由誰發起的連接才可以通過,比如A與B通信,A發給B數據包屬於NEW狀態,B回复給A的數據包就變為ESTABLISHED狀態。ICMP的錯誤和重定向等信息包也被看作是ESTABLISHED,只要它們是我們所發出的信息的應答。
有關 RELATED匹配那些屬於RELATED連接的包,這句話說了跟沒說一樣。RELATED狀態有點複雜,當一個連接與另一個已經是ESTABLISHED的連接有關時,這個連接就被認為是RELATED。這意味著,一個連接要想成為RELATED,必須首先有一個已經是ESTABLISHED的連接存在。這個ESTABLISHED連接再產生一個主連接之外的新連接,這個新連接就是RELATED狀態了,當然首先conntrack模塊要能”讀懂”它是RELATED。拿ftp來說,FTP數據傳輸連接就是RELATED與先前已建立的FTP控制連接,還有通過IRC的DCC連接。有了RELATED這個狀態,ICMP錯誤消息、FTP傳輸、DCC等才能穿過防火牆正常工作。有些依賴此機制的TCP協議和UDP協議非常複雜,他們的連接被封裝在其它的TCP或UDP包的數據部分(可以了解下overlay/vxlan/gre),這使得conntrack需要藉助其它輔助模塊才能正確”讀懂”這些複雜數據包,比如nf_conntrack_ftp這個輔助模塊
無效 INVALID匹配那些無法識別或沒有任何狀態的數據包。這可能是由於系統內存不足或收到不屬於任何已知連接的ICMP錯誤消息。一般情況下我們應該DROP此類狀態的包
未追踪 UNTRACKED狀態比較簡單,它匹配那些帶有NOTRACK標籤的數據包。需要注意的一點是,如果你在raw表中對某些數據包設置有NOTRACK標籤,那上面的4種狀態將無法匹配這樣的數據包,因此你需要單獨考慮NOTRACK包的放行規則
狀態的使用使防火牆可以非常強大和有效,來看下面這個常見的防火牆規則,它允許本機主動訪問外網,以及放開icmp協議
#iptables-save -t filter
*filter
:INPUT DROP [1453341:537074675]
:FORWARD DROP [10976649:6291806497]
:OUTPUT ACCEPT [1221855153:247285484556]
-A INPUT -p icmp -j ACCEPT
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
主機進程與外網機器通信經歷如下步驟,因為除了filter表,其它表沒設置任何規則,所以下面步驟就省略其它表的匹配過程
進程產生要發送的數據包,數據包通過raw錶OUTPUT鍊(可以決定是否要NOTRACK)
數據包通過conntrack,conntrack記錄此連接到連接跟踪表( [UNREPLIED]) – NEW
通過OUTPUT鏈,然後從主機網卡發出– NEW
外網目標主機收到請求,發出響應包
響應包從主機某個接口進入,到達raw錶PREROUTING鍊(可以決定是否要NOTRACK) – NEW
響應包通過conntrack,conntrack發現此數據包為一個連接的響應包,更新對應conntrack條目狀態(去掉[UNREPLIED],至此兩個方向都看到包了) – ESTABLISHED
響應包到達filter錶INPUT鍊,在這裡匹配到--state RELATED,ESTABLISHED,因此放行– ESTABLISHED
像上面這種允許本機主動出流量的需求,如果不用conntrack會很難實現,那你可能會說我也可以使用iptables
數據包在內核中的狀態
從內核角度,不同協議有不同狀態,這裡我們來具體看下三種協議tcp/udp/icmp在連接跟踪表中的不同狀態
tcp連接
下面是172.16.1.100向172.16.1.200建立tcp通信過程中,/proc/net/nf_conntrack中此連接的狀態變化過程
ipv4 2 tcp 6 118 SYN_SENT src=172.16.1.100 dst=172.16.1.200 sport=36884 dport=8220 [UNREPLIED] src=172.16.1.200 dst=172.16.1.100 sport=8220 dport=36884 mark=0 zone=0 use=2
如上,首先172.16.1.100向172.16.1.200發送SYN包,172.16.1.200收到SYN包但尚未回复,由於是新連接,conntrack將此連接添加到連接跟踪表,並標記為SYN_SENT狀態,[UNREPLIED]表示conntrack尚未跟踪到172.16.1.200的響應包。注意上面這條conntrack條目存在於兩台主機的連接跟踪表中(當然,首先要兩台主機都啟用conntrack),對於172.16.1.100,數據包在經過OUTPUT這個hook點時觸發conntrack,而對於172.16.1.200 ,數據包在PREROUTING這個hook點時觸發conntrack
隨後,172.16.1.200回复SYN/ACK包給172.16.1.100,通過conntrack更新連接狀態為SYN_RECV,表示收到SYN/ACk包,去掉[UNREPLIED]字段
ipv4 2 tcp 6 59 SYN_RECV src=172.16.1.100 dst=172.16.1.200 sport=36884 dport=8220 src=172.16.1.200 dst=172.16.1.100 sport=8220 dport=36884 mark=0 zone=0 use=2
接著,172.16.1.100回复ACK給172.16.1.200,至此,三次握手完成,tcp連接已建立,conntrack更新連接狀態為ESTABLISHED
ipv4 2 tcp 6 10799 ESTABLISHED src=172.16.1.100 dst=172.16.1.200 sport=36884 dport=8220 src=172.16.1.200 dst=172.16.1.100 sport=8220 dport=36884 [ASSURED] mark=0 zone=0 use=2
連接跟踪表中的conntrack條目不可能是永久存在,每個conntrack條目都有超時時間,可以如下方式查看tcp連接各個狀態當前設置的超時時間
# sysctl -a |grep 'net.netfilter.nf_conntrack_tcp_timeout_'
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 432000
...
正常的tcp連接是很短暫的,不太可能查看到一個tcp連接所有狀態變化的,那如何構造處於特定狀態的tcp連接呢,一個方法是利用iptables的--tcp-flags參數,其可以匹配tcp數據包的標誌位,比如下面這兩條
#对于本机发往172.16.1.200的tcp数据包,丢弃带有SYN/ACK flag的包
iptables -A OUTPUT -o eth0 -p tcp --tcp-flags SYN,ACK SYN,ACK -d 172.16.1.200 -j DROP
#同样,这个是丢弃带有ACK flag的包
iptables -A OUTPUT -o eth0 -p tcp --tcp-flags ACK ACK -d 172.16.1.100 -j DROP
同時利用tcp超時重傳機制,待cat /proc/net/nf_conntrack獲取到conntrack條目後,使用iptables -D OUTPUT X刪除之前設置的DROP規則,這樣tcp連接就會正常走下去,這個很容易測試出來
udp連接
UDP連接是無狀態的,它沒有連接的建立和關閉過程,連接跟踪表中的udp連接也沒有像tcp那樣的狀態字段,但這不妨礙用戶空間iptables對udp包的狀態匹配,上面也說過,iptables中使用的各個狀態與協議無關
#只收到udp连接第一个包
ipv4 2 udp 17 28 src=172.16.1.100 dst=172.16.1.200 sport=26741 dport=8991 [UNREPLIED] src=172.16.1.200 dst=172.16.1.100 sport=8991 dport=26741 mark=0 zone=0 use=2
#收到此连接的响应包
ipv4 2 udp 17 29 src=172.16.1.100 dst=172.16.1.200 sport=26741 dport=8991 src=172.16.1.200 dst=172.16.1.100 sport=8991 dport=26741 mark=0 zone=0 use=2
同樣可以查看udp超時時間
# sysctl -a | grep 'net.netfilter.nf_conntrack_udp_'
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 180
icmp
icmp請求,在用戶空間iptables看來,跟踪到echo request時連接處於NEW狀態,當有echo reply時就是ESTABLISHED狀態。
#icmp请求
ipv4 2 icmp 1 28 src=103.229.215.2 dst=113.31.136.7 type=8 code=0 id=35102 [UNREPLIED] src=113.31.136.7 dst=103.229.215.2 type=0 code=0 id=35102 mark=0 zone=0 use=2
#reply
ipv4 2 icmp 1 29 src=103.229.215.2 dst=113.31.136.7 type=8 code=0 id=35102 src=113.31.136.7 dst=103.229.215.2 type=0 code=0 id=35102 mark=0 zone=0 use=2
如何管理連接跟踪表
有一個用戶空間工具conntrack,其提供了對連接跟踪表的增刪改查功能,可以用yum install conntrack-tools來安裝,下面是幾個例子
#查看连接跟踪表所有条目
conntrack -L
#清除连接跟踪表
conntrack -F
#删除连接跟踪表中所有源地址是1.2.3.4的条目
conntrack -D -s 1.2.3.4
如果openstack使用安全組IptablesFirewallDriver就會用到這個工具,但默認不會安裝,未安裝時,計算節點neutron-linuxbridge-agent日誌會出現類似下面錯誤
2018-02-14 16:59:42.755 993 ERROR neutron.agent.linux.utils [req-4f84df17-534b-4032-b907-8d3463824726 - - - - -] Rootwrap error running command: ['conntrack', '-D', '-f', 'ipv4', '-d', '172.19.3.99', '-w', '1']
2018-02-14 16:59:42.872 993 ERROR neutron.plugins.ml2.drivers.agent._common_agent self._remove_conntrack_entries_from_port_deleted(port)
需要這個工具是因為在對instance進行安全組/port/ip方面的變更後,需要同時刪除連接跟踪表中舊的相關條目,比如某台instance之前放通本機80端口,某外部主機與此instance 80端口有連接並且有流量,那此時iptables從連接跟踪表中識別到此連接狀態就是ESTABLISHED,然後此時突然有個需求需要禁止本機的80端口,如果不刪除與本機80端口有關的處於ESTABLISHED狀態的conntrack條目,而iptables又會放行處於RELATED,ESTABLISHED狀態的連接,這樣就會造成80端口仍能夠連接
網橋與netfilter
從netfilter框架圖中可以看到,最下層藍色區域為bridge level。Bridge的存在,使得主機可以充當一台虛擬的普通二層交換機來運作,這個虛擬交換機可以建多個port,連接到多個虛擬機。由此帶來的問題是,外部機器與其上虛擬機通信流量只會經過主機二層(靠Bridge轉發,此時不經過主機IP層),主機上的網卡類型變得複雜(物理網卡em1,網橋br0,虛擬網卡vnetX),進入主機的數據包可選路徑變多(bridge轉發/交給主機本地進程)。幸好,netfilter框架都可以解決,這部分內容在我的另一篇文章Bridge與netfilter,相信已經說得夠清楚了。
conntrack與LVS
LVS的修改數據包功能也是依賴netfilter框架,在LVS機器上應用iptables時需要注意一個問題就是,LVS-DR(或LVS-Tun)模式下,不能在director上使用iptables的狀態匹配(NEW,ESTABLISHED, INVALID,…)
LVS-DR模式下,client訪問director,director轉發流量到realserver,realserver直接回复client,不經過director,這種情況下,client與direcotr處於tcp半連接狀態
因此如果在director機器上啟用conntrack,此時conntrack只能看到client–>director的數據包,因為響應包不經過direcotr,conntrack無法看到反方向上的數據包,就表示iptables中的ESTABLISHED狀態永遠無法匹配,從而可能發生DROP
以上就是netfilter框架的內容,理論居多,後續會有一篇專門分析openstack安全組實現的文章,會包括本文大部分知識點,算是作為本文的一個實例應用
netfilter是linux內核中的一個數據包處理框架,用於替代原有的ipfwadm和ipchains等數據包處理程序。netfilter的功能包括數據包過濾,修改,SNAT/DNAT等。netfilter在內核協議棧的不同位置實現了5個hook點,其它內核模塊(比如ip_tables)可以向這些hook點註冊處理函數,這樣當數據包經過這些hook點時,其上註冊的處理函數就被依次調用,用戶層工具像iptables一般都需要相應內核模塊ip_tables配合以完成與netfilter的交互。netfilter hooks、ip{6}_tables、connection tracking、和NAT子系統一起構成了netfilter框架的主要部分。可以參考Netfilter Architecture了解更多內容
下面這張圖來自維基百科netfilter,它展示了netfilter框架在協議棧的位置,你們可能發現這張圖在我的博客中出現多次了,那是因為這張圖太經典了。它可以清楚地看到netfilter框架是如何處理通過不同協議棧路徑上的數據包
網絡過濾器
我們知道iptables的定位是IPv4 packet filter,它只處理IP數據包,而ebtables只工作在鏈路層Link Layer處理的是以太網幀(比如修改源目mac地址)。圖中用有顏色的長方形方框表示iptables或ebtables的表和鏈,綠色小方框表示network level,即iptables的表和鏈。藍色小方框表示bridge level,即ebtables的表和鏈,由於處理以太網幀相對簡單,因此鏈路層的藍色小方框相對較少。
我們還注意到一些代表iptables表和鏈的綠色小方框位於鏈路層,這是因為bridge_nf代碼的作用(從2.6 kernel開始),bridge_nf的引入是為了解決在鏈路層Bridge中處理IP數據包的問題(需要通過內核參數開啟),那為什麼要在鏈路層Bridge中處理IP數據包,而不等數據包通過網絡層時候再處理呢,這是因為不是所有的數據包都一定會通過網絡層,比如外部機器與主機上虛擬機的通信流量,bridge_nf也是openstack中實現安全組功能的基礎。
bridge_nf代碼有時候會引起困惑,就像我們在圖中看到的那樣,代表iptables表和鏈的綠色小方框跑到了鏈路層,netfilter文檔對此也有說明ebtables/iptables interaction on a Linux-based bridge
應當指出,br-nf代碼有時會違反TCP / IP網絡模型。稍後將看到,例如,有可能在鏈路層內部進行IP DNAT
ok,圖中長方形小方框已經解釋清楚了,還有一種橢圓形的方框conntrack,即connection tracking,這是netfilter提供的連接跟踪機制,此機制允許內核”審查”通過此處的所有網絡數據包,並能識別出此數據包屬於哪個網絡連接(比如數據包a屬於IP1:8888->IP2:80這個tcp連接,數據包b屬於ip3:9999->IP4:53這個udp連接)。因此,連接跟踪機制使內核能夠跟踪並記錄通過此處的所有網絡連接及其狀態。圖中可以清楚看到連接跟踪代碼所處的網絡棧位置,如果不想讓某些數據包被跟踪( NOTRACK),那就要找位於橢圓形方框conntrack之前的表和鏈來設置規則。conntrack機制是iptables實現狀態匹配( -m state)以及NAT的基礎,它由單獨的內核模塊nf_conntrack實現。下面還會詳細介紹
接著看圖中左下方bridge check方框,數據包從主機上的某個網絡接口進入( ingress),在bridge check處會檢查此網絡接口是否屬於某個Bridge的port,如果是就會進入Bridge代碼處理邏輯(下方藍色區域bridge level),否則就會送入網絡層Network Layer處理
圖中下方中間位置的bridging decision類似普通二層交換機的查表轉發功能,根據數據包目的MAC地址判斷此數據包是轉發還是交給上層處理,具體可以參考我另一篇文章linux-bridge
圖中中心位置的routing decision就是路由選擇,根據系統路由表( ip route查看),決定數據包是forward,還是交給本地處理
總的來看,不同packet有不同的packet flow,packet總是從主機的某個接口進入(左下方ingress),然後經過check/decision/一系列表和鏈處理,最後,目的地或是主機上某應用進程(上中位置local process),或是需要從主機另一個接口發出(右下方egress)。這裡的接口即可以是物理網卡em1,也可以是虛擬網卡tun0/vnetx,還可以是Bridge上的一個port。
上面就是關於這張圖的一些解釋,如果還有其它疑問,歡迎留言討論,下面說說netfilter框架的各個部分
連接跟踪
當加載內核模塊nf_conntrack後,conntrack機制就開始工作,如上圖,橢圓形方框conntrack在內核中有兩處位置(PREROUTING和OUTPUT之前)能夠跟踪數據包。對於每個通過conntrack的數據包,內核都為其生成一個conntrack條目用以跟踪此連接,對於後續通過的數據包,內核會判斷若此數據包屬於一個已有的連接,則更新所對應的conntrack條目的狀態(比如更新為ESTABLISHED狀態),否則內核會為它新建一個conntrack條目。所有的conntrack條目都存放在一張表裡,稱為連接跟踪表
那麼內核如何判斷一個數據包是否屬於一個已有的連接呢,我們先來了解下連接跟踪表
連接跟踪表
連接跟踪表存放於系統內存中,可以用cat /proc/net/nf_conntrack查看當前跟踪的所有conntrack條目。如下是代表一個tcp連接的conntrack條目,根據連接協議不同,下面顯示的字段信息也不一樣,比如icmp協議
ipv4 2 tcp 6 431955已建立src = 172.16.207.231 dst = 172.16.207.232 sport = 51071 dport = 5672 src = 172.16.207.232 dst = 172.16.207.231 sport = 5672 dport = 51071 [確定] mark = 0區域= use = 2
每個conntrack條目表示一個連接,連接協議可以是tcp,udp,icmp等,它包含了數據包的原始方向信息(藍色)和期望的響應包信息(紅色),這樣內核能夠在後續到來的數據包中識別出屬於此連接的雙向數據包,並更新此連接的狀態,各字段意思的具體分析後面會說。連接跟踪表中能夠存放的conntrack條目的最大值,即係統允許的最大連接跟踪數記作CONNTRACK_MAX
netfilter_hash_table
在內核中,連接跟踪表是一個二維數組結構的哈希表(hash table),哈希表的大小記作HASHSIZE,哈希表的每一項(hash table entry)稱作bucket,因此哈希表中有HASHSIZE個bucket存在,每個bucket包含一個鍊錶(linked list),每個鍊錶能夠存放若干個conntrack條目( bucket size)。對於一個新收到的數據包,內核使用如下步驟判斷其是否屬於一個已有連接:
內核提取此數據包信息(源目IP,port,協議號)進行hash計算得到一個hash值,在哈希表中以此hash值做索引,索引結果為數據包所屬的bucket(鍊錶)。這一步hash計算時間固定並且很短
遍歷hash得到的bucket,查找是否有匹配的conntrack條目。這一步是比較耗時的操作,bucket size越大,遍歷時間越長
如何設置最大連接跟踪數
根據上面對哈希表的解釋,系統最大允許連接跟踪數CONNTRACK_MAX= 连接跟踪表大小(HASHSIZE) * Bucket大小(bucket size)。從連接跟踪表獲取bucket是hash操作時間很短,而遍歷bucket相對費時,因此為了conntrack性能考慮,bucket size越小越好,默認為8
#查看系统当前最大连接跟踪数CONNTRACK_MAX
sysctl -a | grep net.netfilter.nf_conntrack_max
#net.netfilter.nf_conntrack_max = 3203072
#查看当前连接跟踪表大小HASHSIZE
sysctl -a | grep net.netfilter.nf_conntrack_buckets
#400384
#或者这样
cat /sys/module/nf_conntrack/parameters/hashsize
#400384
這兩個的比值即為bucket size = 3203072 / 400384
如下,現在需求是設置系統最大連接跟踪數為320w,由於bucket size不能直接設置,為了使bucket size值為8,我們需要同時設置CONNTRACK_MAX和HASHSIZE,因為他們的比值就是bucket size
#HASHSIZE (内核会自动格式化为最接近允许值)
echo 400000 > /sys/module/nf_conntrack/parameters/hashsize
#系统最大连接跟踪数
sysctl -w net.netfilter.nf_conntrack_max=3200000
#注意nf_conntrack内核模块需要加载
為了使nf_conntrack模塊重新加載或系統重啟後生效
#nf_conntrack模块提供了设置HASHSIZE的参数
echo "options nf_conntrack hashsize=400000" > /etc/modprobe.d/nf_conntrack.conf
只需要固化HASHSIZE值,nf_conntrack模塊在重新加載時會自動設置CONNTRACK_MAX = hashsize * 8,當然前提是你bucket size使用系統默認值8。如果自定義bucket size值,就需要同時固化CONNTRACK_MAX,以保持其比值為你想要的bucket size
上面我們沒有改變bucket size的默認值8,但是若內存足夠並且性能很重要,你可以考慮每個bucket一個conntrack條目( bucket size= 1),最大可能降低遍歷耗時,即HASHSIZE = CONNTRACK_MAX
#HASHSIZE
echo 3200000 > /sys/module/nf_conntrack/parameters/hashsize
#CONNTRACK_MAX
sysctl -w net.netfilter.nf_conntrack_max=3200000
如何計算連接跟踪所佔內存
連接跟踪表存儲在系統內存中,因此需要考慮內存佔用問題,可以用下面公式計算設置不同的最大連接跟踪數所佔最大系統內存
total_mem_used(bytes) = CONNTRACK_MAX * sizeof(struct ip_conntrack) + HASHSIZE * sizeof(struct list_head)
例如我們需要設置最大連接跟踪數為320w,在centos6/7系統上,sizeof(struct ip_conntrack)= 376,sizeof(struct list_head)= 16,並且bucket size使用默認值8,並且HASHSIZE = CONNTRACK_MAX / 8,因此
total_mem_used(bytes) = 3200000 * 376 + (3200000 / 8) * 16
# = 1153MB ~= 1GB
因此可以得到,在centos6/7系統上,設置320w的最大連接跟踪數,所消耗的內存大約為1GB,對現代服務器來說,佔用內存並不多,但conntrack實在讓人又愛又恨
關於上面兩個sizeof(struct *)值在你係統上的大小,如果會C就好說,如果不會,可以使用如下python代碼計算
import ctypes
#不同系统可能此库名不一样,需要修改
LIBNETFILTER_CONNTRACK = 'libnetfilter_conntrack.so.3.6.0'
nfct = ctypes.CDLL(LIBNETFILTER_CONNTRACK)
print 'sizeof(struct nf_conntrack):', nfct.nfct_maxsize()
print 'sizeof(struct list_head):', ctypes.sizeof(ctypes.c_void_p) * 2
conntrack條目
conntrack從經過它的數據包中提取詳細的,唯一的信息,因此能保持對每一個連接的跟踪。關於conntrack如何確定一個連接,對於tcp/udp,連接由他們的源目地址,源目端口唯一確定。對於icmp,由type,code和id字段確定。
ipv4 2 tcp 6 33 SYN_SENT src=172.16.200.119 dst=172.16.202.12 sport=54786 dport=10051 [UNREPLIED] src=172.16.202.12 dst=172.16.200.119 sport=10051 dport=54786 mark=0 zone=0 use=2
如上是一條conntrack條目,它代表當前已跟踪到的某個連接,conntrack維護的所有信息都包含在這個條目中,通過它就可以知道某個連接處於什麼狀態
此連接使用ipv4協議,是一條tcp連接(tcp的協議類型代碼是6)
33是這條conntrack條目在當前時間點的生存時間(每個conntrack條目都會有生存時間,從設置值開始倒計時,倒計時完後此條目將被清除),可以使用sysctl -a |grep conntrack | grep timeout查看不同協議不同狀態下生存時間設置值,當然這些設置值都可以調整,注意若後續有收到屬於此連接的數據包,則此生存時間將被重置(重新從設置值開始倒計時),並且狀態改變,生存時間設置值也會響應改為新狀態的值
SYN_SENT是到此刻為止conntrack跟踪到的這個連接的狀態(內核角度),SYN_SENT表示這個連接只在一個方向發送了一初始TCP SYN包,還未看到響應的SYN+ACK包(只有tcp才會有這個字段)。
src=172.16.200.119 dst=172.16.202.12 sport=54786 dport=10051是從數據包中提取的此連接的源目地址、源目端口,是conntrack首次看到此數據包時候的信息。
[UNREPLIED]說明此刻為止這個連接還沒有收到任何響應,當一個連接已收到響應時,[UNREPLIED]標誌就會被移除
接下來的src=172.16.202.12 dst=172.16.200.119 sport=10051 dport=54786地址和端口和前面是相反的,這部分不是數據包中帶有的信息,是conntrack填充的信息,代表conntrack希望收到的響應包信息。意思是若後續conntrack跟踪到某個數據包信息與此部分匹配,則此數據包就是此連接的響應數據包。注意這部分確定了conntrack如何判斷響應包(tcp/udp),icmp是依據另外幾個字段
上面是tcp連接的條目,而udp和icmp沒有連接建立和關閉過程,因此條目字段會有所不同,後面iptables狀態匹配部分我們會看到處於各個狀態的conntrack條目
注意conntrack機制並不能夠修改或過濾數據包,它只是跟踪網絡連接並維護連接跟踪表,以提供給iptables做狀態匹配使用,也就是說,如果你iptables中用不到狀態匹配,那就沒必要啟用conntrack
iptables狀態匹配
本部分參考自iptables文檔iptables-tutorial#The state machine,我找不到比它更全面的文章了
先明確下conntrack在內核協議棧所處位置,上面也提過conntrack跟踪數據包的位置在PREROUTING和OUTPUT這兩個hook點,主機自身進程產生的數據包會通過OUTPUT處的conntrack,從主機任意接口進入(包括Bridge的port)的數據包會通過PREROUTING處的conntrack,從netfilter框架圖上可以看到conntrack位置很靠前,僅在iptables的raw表之後,raw表主要作用就是允許我們對某些特定的數據包打上NOTRACK標記,這樣後面的conntrack就不會記錄此類帶有NOTRACK標籤的數據包。conntrack位置很靠前一方面是保證其後面的iptables表和鏈都能使用狀態匹配,另一方面使得conntrack能夠跟踪到任何進出主機的原始數據包(比如數據包還未NAT/FORWARD)。
iptables狀態匹配模塊
iptables狀態
iptables是帶有狀態匹配的防火牆,它使用-m state模塊從連接跟踪表查找數據包狀態。上面我們分析的那條conntrack條目處於SYN_SENT狀態,這是內核記錄的狀態,數據包在內核中可能會有幾種不同的狀態,但是映射到用戶空間iptables,只有5種狀態可用:NEW,ESTABLISHED,RELATED ,INVALID和UNTRACKED。注意這裡說的狀態不是tcp/ip協議中tcp連接的各種狀態。下面表格說明了這5種狀態分別能夠匹配什麼樣的數據包,注意下面兩點
用戶空間這5種狀態是iptables用於完成狀態匹配而定義的,不關聯與特定連接協議
conntrack記錄在前,iptables匹配在後(見netfilter框架圖)
狀態 解釋
新 NEW匹配連接的第一個包。意思就是,iptables從連接跟踪表中查到此包是某連接的第一個包。判斷此包是某連接的第一個包是依據conntrack當前”只看到一個方向數據包”( [UNREPLIED]),不關聯特定協議,因此NEW並不單指tcp連接的SYN包
已建立 ESTABLISHED匹配連接的響應包及後續的包。意思是,iptables從連接跟踪表中查到此包是屬於一個已經收到響應的連接(即沒有[UNREPLIED]字段)。因此在iptables狀態中,只要發送並接到響應,連接就認為是ESTABLISHED的了。這個特點使iptables可以控制由誰發起的連接才可以通過,比如A與B通信,A發給B數據包屬於NEW狀態,B回复給A的數據包就變為ESTABLISHED狀態。ICMP的錯誤和重定向等信息包也被看作是ESTABLISHED,只要它們是我們所發出的信息的應答。
有關 RELATED匹配那些屬於RELATED連接的包,這句話說了跟沒說一樣。RELATED狀態有點複雜,當一個連接與另一個已經是ESTABLISHED的連接有關時,這個連接就被認為是RELATED。這意味著,一個連接要想成為RELATED,必須首先有一個已經是ESTABLISHED的連接存在。這個ESTABLISHED連接再產生一個主連接之外的新連接,這個新連接就是RELATED狀態了,當然首先conntrack模塊要能”讀懂”它是RELATED。拿ftp來說,FTP數據傳輸連接就是RELATED與先前已建立的FTP控制連接,還有通過IRC的DCC連接。有了RELATED這個狀態,ICMP錯誤消息、FTP傳輸、DCC等才能穿過防火牆正常工作。有些依賴此機制的TCP協議和UDP協議非常複雜,他們的連接被封裝在其它的TCP或UDP包的數據部分(可以了解下overlay/vxlan/gre),這使得conntrack需要藉助其它輔助模塊才能正確”讀懂”這些複雜數據包,比如nf_conntrack_ftp這個輔助模塊
無效 INVALID匹配那些無法識別或沒有任何狀態的數據包。這可能是由於系統內存不足或收到不屬於任何已知連接的ICMP錯誤消息。一般情況下我們應該DROP此類狀態的包
未追踪 UNTRACKED狀態比較簡單,它匹配那些帶有NOTRACK標籤的數據包。需要注意的一點是,如果你在raw表中對某些數據包設置有NOTRACK標籤,那上面的4種狀態將無法匹配這樣的數據包,因此你需要單獨考慮NOTRACK包的放行規則
狀態的使用使防火牆可以非常強大和有效,來看下面這個常見的防火牆規則,它允許本機主動訪問外網,以及放開icmp協議
#iptables-save -t filter
*filter
:INPUT DROP [1453341:537074675]
:FORWARD DROP [10976649:6291806497]
:OUTPUT ACCEPT [1221855153:247285484556]
-A INPUT -p icmp -j ACCEPT
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
主機進程與外網機器通信經歷如下步驟,因為除了filter表,其它表沒設置任何規則,所以下面步驟就省略其它表的匹配過程
進程產生要發送的數據包,數據包通過raw錶OUTPUT鍊(可以決定是否要NOTRACK)
數據包通過conntrack,conntrack記錄此連接到連接跟踪表( [UNREPLIED]) – NEW
通過OUTPUT鏈,然後從主機網卡發出– NEW
外網目標主機收到請求,發出響應包
響應包從主機某個接口進入,到達raw錶PREROUTING鍊(可以決定是否要NOTRACK) – NEW
響應包通過conntrack,conntrack發現此數據包為一個連接的響應包,更新對應conntrack條目狀態(去掉[UNREPLIED],至此兩個方向都看到包了) – ESTABLISHED
響應包到達filter錶INPUT鍊,在這裡匹配到--state RELATED,ESTABLISHED,因此放行– ESTABLISHED
像上面這種允許本機主動出流量的需求,如果不用conntrack會很難實現,那你可能會說我也可以使用iptables
數據包在內核中的狀態
從內核角度,不同協議有不同狀態,這裡我們來具體看下三種協議tcp/udp/icmp在連接跟踪表中的不同狀態
tcp連接
下面是172.16.1.100向172.16.1.200建立tcp通信過程中,/proc/net/nf_conntrack中此連接的狀態變化過程
ipv4 2 tcp 6 118 SYN_SENT src=172.16.1.100 dst=172.16.1.200 sport=36884 dport=8220 [UNREPLIED] src=172.16.1.200 dst=172.16.1.100 sport=8220 dport=36884 mark=0 zone=0 use=2
如上,首先172.16.1.100向172.16.1.200發送SYN包,172.16.1.200收到SYN包但尚未回复,由於是新連接,conntrack將此連接添加到連接跟踪表,並標記為SYN_SENT狀態,[UNREPLIED]表示conntrack尚未跟踪到172.16.1.200的響應包。注意上面這條conntrack條目存在於兩台主機的連接跟踪表中(當然,首先要兩台主機都啟用conntrack),對於172.16.1.100,數據包在經過OUTPUT這個hook點時觸發conntrack,而對於172.16.1.200 ,數據包在PREROUTING這個hook點時觸發conntrack
隨後,172.16.1.200回复SYN/ACK包給172.16.1.100,通過conntrack更新連接狀態為SYN_RECV,表示收到SYN/ACk包,去掉[UNREPLIED]字段
ipv4 2 tcp 6 59 SYN_RECV src=172.16.1.100 dst=172.16.1.200 sport=36884 dport=8220 src=172.16.1.200 dst=172.16.1.100 sport=8220 dport=36884 mark=0 zone=0 use=2
接著,172.16.1.100回复ACK給172.16.1.200,至此,三次握手完成,tcp連接已建立,conntrack更新連接狀態為ESTABLISHED
ipv4 2 tcp 6 10799 ESTABLISHED src=172.16.1.100 dst=172.16.1.200 sport=36884 dport=8220 src=172.16.1.200 dst=172.16.1.100 sport=8220 dport=36884 [ASSURED] mark=0 zone=0 use=2
連接跟踪表中的conntrack條目不可能是永久存在,每個conntrack條目都有超時時間,可以如下方式查看tcp連接各個狀態當前設置的超時時間
# sysctl -a |grep 'net.netfilter.nf_conntrack_tcp_timeout_'
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 432000
...
正常的tcp連接是很短暫的,不太可能查看到一個tcp連接所有狀態變化的,那如何構造處於特定狀態的tcp連接呢,一個方法是利用iptables的--tcp-flags參數,其可以匹配tcp數據包的標誌位,比如下面這兩條
#对于本机发往172.16.1.200的tcp数据包,丢弃带有SYN/ACK flag的包
iptables -A OUTPUT -o eth0 -p tcp --tcp-flags SYN,ACK SYN,ACK -d 172.16.1.200 -j DROP
#同样,这个是丢弃带有ACK flag的包
iptables -A OUTPUT -o eth0 -p tcp --tcp-flags ACK ACK -d 172.16.1.100 -j DROP
同時利用tcp超時重傳機制,待cat /proc/net/nf_conntrack獲取到conntrack條目後,使用iptables -D OUTPUT X刪除之前設置的DROP規則,這樣tcp連接就會正常走下去,這個很容易測試出來
udp連接
UDP連接是無狀態的,它沒有連接的建立和關閉過程,連接跟踪表中的udp連接也沒有像tcp那樣的狀態字段,但這不妨礙用戶空間iptables對udp包的狀態匹配,上面也說過,iptables中使用的各個狀態與協議無關
#只收到udp连接第一个包
ipv4 2 udp 17 28 src=172.16.1.100 dst=172.16.1.200 sport=26741 dport=8991 [UNREPLIED] src=172.16.1.200 dst=172.16.1.100 sport=8991 dport=26741 mark=0 zone=0 use=2
#收到此连接的响应包
ipv4 2 udp 17 29 src=172.16.1.100 dst=172.16.1.200 sport=26741 dport=8991 src=172.16.1.200 dst=172.16.1.100 sport=8991 dport=26741 mark=0 zone=0 use=2
同樣可以查看udp超時時間
# sysctl -a | grep 'net.netfilter.nf_conntrack_udp_'
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 180
icmp
icmp請求,在用戶空間iptables看來,跟踪到echo request時連接處於NEW狀態,當有echo reply時就是ESTABLISHED狀態。
#icmp请求
ipv4 2 icmp 1 28 src=103.229.215.2 dst=113.31.136.7 type=8 code=0 id=35102 [UNREPLIED] src=113.31.136.7 dst=103.229.215.2 type=0 code=0 id=35102 mark=0 zone=0 use=2
#reply
ipv4 2 icmp 1 29 src=103.229.215.2 dst=113.31.136.7 type=8 code=0 id=35102 src=113.31.136.7 dst=103.229.215.2 type=0 code=0 id=35102 mark=0 zone=0 use=2
如何管理連接跟踪表
有一個用戶空間工具conntrack,其提供了對連接跟踪表的增刪改查功能,可以用yum install conntrack-tools來安裝,下面是幾個例子
#查看连接跟踪表所有条目
conntrack -L
#清除连接跟踪表
conntrack -F
#删除连接跟踪表中所有源地址是1.2.3.4的条目
conntrack -D -s 1.2.3.4
如果openstack使用安全組IptablesFirewallDriver就會用到這個工具,但默認不會安裝,未安裝時,計算節點neutron-linuxbridge-agent日誌會出現類似下面錯誤
2018-02-14 16:59:42.755 993 ERROR neutron.agent.linux.utils [req-4f84df17-534b-4032-b907-8d3463824726 - - - - -] Rootwrap error running command: ['conntrack', '-D', '-f', 'ipv4', '-d', '172.19.3.99', '-w', '1']
2018-02-14 16:59:42.872 993 ERROR neutron.plugins.ml2.drivers.agent._common_agent self._remove_conntrack_entries_from_port_deleted(port)
需要這個工具是因為在對instance進行安全組/port/ip方面的變更後,需要同時刪除連接跟踪表中舊的相關條目,比如某台instance之前放通本機80端口,某外部主機與此instance 80端口有連接並且有流量,那此時iptables從連接跟踪表中識別到此連接狀態就是ESTABLISHED,然後此時突然有個需求需要禁止本機的80端口,如果不刪除與本機80端口有關的處於ESTABLISHED狀態的conntrack條目,而iptables又會放行處於RELATED,ESTABLISHED狀態的連接,這樣就會造成80端口仍能夠連接
網橋與netfilter
從netfilter框架圖中可以看到,最下層藍色區域為bridge level。Bridge的存在,使得主機可以充當一台虛擬的普通二層交換機來運作,這個虛擬交換機可以建多個port,連接到多個虛擬機。由此帶來的問題是,外部機器與其上虛擬機通信流量只會經過主機二層(靠Bridge轉發,此時不經過主機IP層),主機上的網卡類型變得複雜(物理網卡em1,網橋br0,虛擬網卡vnetX),進入主機的數據包可選路徑變多(bridge轉發/交給主機本地進程)。幸好,netfilter框架都可以解決,這部分內容在我的另一篇文章Bridge與netfilter,相信已經說得夠清楚了。
conntrack與LVS
LVS的修改數據包功能也是依賴netfilter框架,在LVS機器上應用iptables時需要注意一個問題就是,LVS-DR(或LVS-Tun)模式下,不能在director上使用iptables的狀態匹配(NEW,ESTABLISHED, INVALID,…)
LVS-DR模式下,client訪問director,director轉發流量到realserver,realserver直接回复client,不經過director,這種情況下,client與direcotr處於tcp半連接狀態
因此如果在director機器上啟用conntrack,此時conntrack只能看到client–>director的數據包,因為響應包不經過direcotr,conntrack無法看到反方向上的數據包,就表示iptables中的ESTABLISHED狀態永遠無法匹配,從而可能發生DROP
以上就是netfilter框架的內容,理論居多,後續會有一篇專門分析openstack安全組實現的文章,會包括本文大部分知識點,算是作為本文的一個實例應用
2020年5月12日 星期二
Ethernet PHY Abstraction Layer 與驅動程式的徹底了解
PHY的抽象層
大多數網路裝置包含MAC與PHY,MAC透過一組暫存器與系統連接,MAC層通過PHY與網路的實體層連接進行通信。
PHY負責與Ethernet連接,並提供暫存器接口以允許Linux驅動程式來查詢網路的設置。PHY通常是一顆晶片,系統存取他的方式是透過MDIO BUS。下面先看一下MDIO BUS的驅動方式:
MDIO BUS
系統也許會有兩個以上的PHY,所以會有不同的MDIO BUS來連接PHY。
1. MDIO BUS必須要有的基本讀寫功能:
int write(struct mii_bus *bus, int mii_id, int regnum, u16 value);
int read(struct mii_bus *bus, int mii_id, int regnum);
mii_id是PHY BUS的地址,regnum 是暫存器編號。這兩個API都必須保證,系統處理中斷的時間,不會調用這些函數,因此要安全地BLOCK它們,等待中斷完成之後,才會被調用。
2. RESET功能是可選的。這用於使NUS回到初始化的狀態。
3. Probe功能是必要的。這函數應設置BUS驅動程序所需的任何資料結構,設定 mii_bus 資料結構,並使用 mdiobus_register向PAL註冊。同樣,mdiobus_unregister可以註銷所有功能(使用)。
4. 像任何驅動程序一樣,必須配置device_driver資料結構,並使用init exit 來註冊驅動程序。
5. BUS也必須在某處宣告為設備,並進行註冊。
mdio bus driver 範例位於 drivers/net/phy/realtek.c
RGMII 電氣特性注意事項:
RGMII 是12針的電信號接口,使用同步125 MHz 時鐘信號和幾條數據線。由於此設計決定,必須在Clock 時鐘線 (RXC 或TXC )和Data Lines 之間添加 1.5ns 至 2ns 的延遲,以使PHY(時鐘接收器)具有足夠大的建立和保持時間以正確採樣 Data Lines。
PHY Library 提供了不同類型的PHY_INTERFACE_MODE_RGMII 值,以使PHY驅動程序以及可選的MAC驅動程序實現所需的延遲。必須從PHY設備本身的角度理解 phy_interface_t 的值,這導致:
PHY_INTERFACE_MODE_RGMII:PHY本身不負責插入任何內部延遲,它假設Ethernet MAC或PCB走線會插入正確的 1.5-2 ns 延遲。
PHY_INTERFACE_MODE_RGMII_TXID:PHY應該為PHY設備處理的發送數據線(TXD [3:0])插入內部延遲。
PHY_INTERFACE_MODE_RGMII_RXID:PHY應該為由PHY設備處理的接收數據線(RXD [3:0])插入內部延遲。
PHY_INTERFACE_MODE_RGMII_ID:PHY應該為來自/去往PHY設備的發送和接收數據線插入內部延遲
出於以下原因,請盡可能使用PHY端RGMII延遲:
1. PHY可以提供 sub-nanosecond 等級的延遲(例如:0.5、1.0、1.5ns)。如果使用PCB走線,因為長度的差異,可能能以達到這種精度。
2. PHY設備可以在溫度/壓力/電壓範圍內提供恆定且可靠的延遲。
PHYLIB中的PHY設備驅動程序本質上是可重用的,能夠正確配置指定的延遲,從而使更多具有類似延遲要求的設計能夠正確運行
對於PHY無法提供此延遲但以太網MAC驅動程序能夠提供此延遲的情況,正確的phy_interface_t值應為PHY_INTERFACE_MODE_RGMII,並且應正確配置以太網MAC驅動程序以提供所需的發送和/或從PHY設備的角度接收側延遲。相反,如果以太網MAC驅動程序查看phy_interface_t值,則對於除PHY_INTERFACE_MODE_RGMII之外的任何其他模式,都應確保禁用了MAC級延遲。
如果按照RGMII標准定義,以太網MAC和PHY均不能提供所需的延遲,則可能有幾種選擇:
某些SoC可能會提供一個引腳墊/多路復用器/控制器,能夠配置一組給定的引腳強度,延遲和電壓。並且插入預期的2ns RGMII延遲可能是合適的選擇。
修改PCB設計以包括固定的延遲(例如:使用專門設計的蛇形),這可能根本不需要軟件配置。
與RGMII延遲失配的常見問題
當以太網MAC和PHY之間存在RGMII延遲不匹配時,當PHY或MAC對這些信號進行快照以將它們轉換為邏輯1或0狀態時,這很可能導致時鐘和數據線信號不穩定並重建正在發送/接收的數據。典型症狀包括:
傳輸/接收部分起作用,並且觀察到頻繁或偶發的數據包丟失。
以太網MAC可能報告一些或所有進入FCS / CRC錯誤的數據包,或者只是丟棄所有這些數據包。
切換到較低的速度(例如10 / 100Mbits /秒)可以解決問題(因為在這種情況下有足夠的建立/保持時間)。
連接到在啟動過程中的某個時候,網路驅動程序需要在PHY設備和網路設備之間建立連接。這時,PHY的總線和驅動程序都已加載完畢,因此可以進行連接了。此時,有幾種方法可以連接到PHY:
讓PHY抽象層做所有事情
如果選擇選項1(希望每個驅動程序都可以,但對於不能驅動的驅動程序仍然有用),則連接到PHY很簡單:
首先,您需要一個函數來響應鏈接狀態的變化。此功能遵循以下協議:
static void adjust_link(struct net_device *dev);
接下來,您需要知道連接到該設備的PHY的設備名稱。名稱將看起來像“ 0:00”,其中第一個數字是總線ID,第二個數字是該總線上PHY的地址。通常,總線負責使其ID唯一。
現在,要連接,只需調用此函數:
phydev = phy_connect(dev, phy_name, &adjust_link, interface);
phydev是指向表示PHY的phy_device結構的指針。如果phy_connect成功,它將返回指針。dev在這裡是指向net_device的指針。一旦完成,該功能將啟動PHY的軟件狀態機,並為PHY的中斷註冊(如果有)。PHYdev結構將填充有關當前狀態的信息,儘管此時PHY尚未真正運行。
在調用之前,應在phydev-> dev_flags中設置PHY特定的標誌phy_connect(),以便底層PHY驅動程式可以檢查標誌並基於它們執行特定的操作。如果系統對PHY /控制器施加了硬件限制,而PHY需要了解這些限制,則這將很有用。
接口是一個u32,它指定控制器和PHY之間使用的連接類型。實例是GMII,MII,RGMII和SGMII。請參見下面的“ PHY接口模式”。有關完整列表,請參見include / linux / phy.h
現在只需確保phydev-> supported和phydev-> advertising都從它們中刪除了對您的控制器沒有意義的任何值 (10/100控制器可能已連接到具有千兆位功能的PHY,因此您需要屏蔽關閉SUPPORTED_1000baseT *)。
有關這些位域的定義,請參見 include / linux / ethtool.h。請注意,除了SUPPORTED_Pause和SUPPORTED_AsymPause位(請參見下文)外,您不應該設置任何位,否則PHY可能會進入不受支持的狀態。
最後,一旦控制器準備好處理網路流量,就可以調用phy_start(phydev)。這告訴PAL您已準備就緒,並配置PHY以連接到網路。如果網路驅動程式的MAC中斷也處理PHY狀態更改,則只需在將phydev-> irq設置為PHY_IGNORE_INTERRUPT,然後再phy_mac_interrupt()從網路驅動程式調用phy_start並使用它即可。如果不想使用中斷,請將phydev-> irq設置為PHY_POLL。 phy_start()啟用PHY中斷(如果適用)並啟動phylib狀態機。
如果要斷開網路連接(即使只是短暫斷開連接),請調用 phy_stop(phydev)。此功能還可以停止phylib狀態機並禁用PHY中斷。
PHY接口模式
phy_connect()功能係列中提供的PHY接口模式定義了PHY接口的初始操作模式。這不能保證保持恆定。有些PHY會根據協商結果動態更改其接口模式,而無需軟件交互。
一些接口模式如下所述:
PHY_INTERFACE_MODE_1000BASEX
這定義了802.3標準第36條所定義的1000BASE-X單通道Serdes鏈接。該鏈接使用10B / 8B編碼方案以1.25Gbaud的固定位速率運行,從而產生1Gbps的基礎數據速率。數據流中嵌入了一個16位控製字,用於與遠端協商雙工和暫停模式。這不包括“超頻”變體,例如2.5Gbps速度(請參閱下文)。
PHY_INTERFACE_MODE_2500BASEX
這定義了1000BASE-X的變體,其時鐘頻率比802.3標準快2.5倍,後者提供了3.125Gbaud的固定比特率。
PHY_INTERFACE_MODE_SGMII
這用於Cisco SGMII,它是對802.3標准定義的1000BASE-X的修改。SGMII鏈路由一條串行SERDES通道組成,該通道以1.25Gbaud的固定比特率運行,具有10B / 8B編碼。基本數據速率為1Gbps,通過複製每個數據符號可實現100Mbps和10Mbps的較慢速度。802.3控製字的用途是重新發送協商的速度和雙工信息到MAC,並讓MAC確認接收。這不包括“超頻”變體,例如2.5Gbps速度。
注意:在某些情況下,鏈路上的SGMII與1000BASE-X配置不匹配可以成功傳遞數據,但是16位控製字將無法正確解釋,這可能導致雙工,暫停或其他設置不匹配。這取決於MAC和/或PHY行為。
PHY_INTERFACE_MODE_10GBASER
這是IEEE 802.3條款49定義的10GBASE-R協議,可用於各種不同的介質。有關此定義,請參考IEEE標準。
注意:10GBASE-R只是可以與XFI和SFI一起使用的一種協議。XFI和SFI允許在單個SERDES通道上使用多種協議,並且通過將主機兼容板插入主機XFP / SFP連接器來定義信號的電氣特性。因此,XFI和SFI本身並不是PHY接口類型。
PHY_INTERFACE_MODE_10GKR
這是IEEE 802.3條款49定義的帶有條款73自動協商的10GBASE-R。請參考IEEE標準以獲取更多信息。
暫停Bit/流量控制
PHY不會直接參與流控制/暫停Bit,除非確保在MII_ADVERTISE中將SUPPORTED_Pause和SUPPORTED_AsymPause位設置為向鏈路夥伴,表明以太網MAC控制器支持這種情況。由於流控制/暫停幀的生成涉及以太網MAC驅動程式,因此建議該驅動程式通過相應地設置SUPPORTED_Pause和SUPPORTED_AsymPause位來適當地指示廣告和對此類功能的支持。可以在 phy_connect() 實現 ethtool :: set_pauseparam功能之前或之後和/或作為結果。
在PAL上保持關閉選項卡
PAL的內置狀態機可能需要一點幫助,以使您的網路設備和PHY正確同步。如果是這樣,您可以在連接到PHY時註冊一個輔助函數,該函數將在狀態機對任何更改做出反應之前每秒調用一次。為此,您需要手動調用phy_attach()和phy_prepare_link(),然後phy_start_machine()在第二個參數設置為指向您的特殊處理程序的情況下進行調用 。
當前尚無有關如何使用此功能的示例,並且由於作者沒有使用該功能的驅動程式(它們全部使用選項1),因此對其進行的測試受到限制。因此,警告皇帝。
自己動手做
PAL的內置狀態機極有可能無法跟踪PHY與您的網路設備之間的複雜交互。如果是這樣,您可以直接調用phy_attach(),而不能調用phy_start_machine或 phy_prepare_link()。這將意味著phydev-> state完全由您處理(phy_start和phy_stop在某些狀態之間切換,因此您可能需要避免它們)。
已經做出努力以確保可以在不運行狀態機的情況下訪問有用的功能,並且這些功能中的大多數是未與復雜狀態機交互的功能的後繼功能。但是,到目前為止,在沒有狀態機的情況下,到目前為止尚未做出任何努力來測試運行情況,因此請謹慎嘗試。
以下是這些功能的簡要概述:
int phy_read(struct phy_device *phydev, u16 regnum);
int phy_write(struct phy_device *phydev, u16 regnum, u16 val);
簡單的讀/寫原語。它們調用總線的讀/寫功能指針。
void phy_print_status(struct phy_device *phydev);
方便的功能可以整齊地打印PHY狀態。
void phy_request_interrupt(struct phy_device *phydev);
請求PHY中斷的IRQ。
struct phy_device * phy_attach(struct net_device *dev, const char *phy_id,
phy_interface_t interface);
將網路設備連接到特定的PHY,如果在總線初始化期間未找到PHY,則將PHY綁定到通用驅動程式。
int phy_start_aneg(struct phy_device *phydev);
使用phydev結構內部的變量,可以配置廣告並重置自動協商,或者禁用自動協商並配置強制設置。
static inline int phy_read_status(struct phy_device *phydev);
用有關PHY中當前設置的最新信息填充phydev結構。
int phy_ethtool_ksettings_set(struct phy_device *phydev,
const struct ethtool_link_ksettings *cmd);
Ethtool便利功能。
int phy_mii_ioctl(struct phy_device *phydev,
struct mii_ioctl_data *mii_data, int cmd);
MII ioctl。請注意,如果您寫入諸如BMCR,BMSR,ADVERTISE等暫存器,則此功能將完全破壞狀態機。最好僅使用此功能來寫入非標準的暫存器,並且不要啟動重新協商。
PHY Device Driver (設備驅動程序)
借助PHY抽象層,添加對新PHY的支持非常容易。有時候,根本沒有工作要做。
Generic PHY driver
這是最常用的驅動程式。
編寫PHY驅動程式
如果確實需要編寫PHY驅動程式,可以參考一下的說明。
首先要在BUS初始化的時候,先讀取裝置的UID (儲存在暫存器2和3之中),然後通過將其與每個驅動程式的 phy_id 字段與每個驅動程式的phy_id_mask字段,進行“與”操作進行比較來完成的。另外,它需要一個名稱。以下是一個例子:
static struct phy_driver dm9161_driver = {
.phy_id = 0x0181b880,
.name = "Davicom DM9161E",
.phy_id_mask = 0x0ffffff0,
...
}
接下來,您需要指定PHY設備和驅動程式支持哪些功能 ( speed, duplex, autoreg )。大多數PHY支持 PHY_BASIC_FEATURES,但是您可以在 #include/mii.h中查找其他功能。
每個驅動程式由許多函數 pointer 組成,這些point定義於 #include/linux/phy.h 檔案中struct phy_driver。
/*
struct phy_driver: Driver structure for a particular PHY type driver_data: static driver data
phy_id: The result of reading the UID registers of this PHY type, and ANDing them with the phy_id_mask. This driver only works for PHYs with IDs which match this field name: The friendly name of this PHY type phy_id_mask: Defines the important bits of the phy_id features:
A mandatory list of features (speed, duplex, etc) supported by this PHY flags: A bitfield defining certain other features this PHY supports (like interrupts)
All functions are optional. If config_aneg or read_status are not implemented, the phy core uses the genphy versions. Note that none of these functions should be called from interrupt time. The goal is for the bus read/write functions to be able to block when the bus transaction is happening, and be freed up by an interrupt (The MPC85xx has this ability, though it is not currently supported in the driver).
*/
struct phy_driver {
struct mdio_driver_common mdiodrv;
u32 phy_id;
char *name;
u32 phy_id_mask;
const unsigned long * const features;
u32 flags;
const void *driver_data;
/*
* Called to issue a PHY software reset
*/
int (*soft_reset)(struct phy_device *phydev);
/*
* Called to initialize the PHY, including after a reset
*/
int (*config_init)(struct phy_device *phydev);
/*
* Called during discovery. Used to set up device-specific structures, if any
*/
int (*probe)(struct phy_device *phydev);
/*
* Probe the hardware to determine what abilities it has. Should only set phydev->supported.
*/
int (*get_features)(struct phy_device *phydev);
/* PHY Power Management */
int (*suspend)(struct phy_device *phydev);
int (*resume)(struct phy_device *phydev);
/*
* Configures the advertisement and resets autonegotiation if phydev->autoneg is on,
* forces the speed to the current settings in phydev, if phydev->autoneg is off
*/
int (*config_aneg)(struct phy_device *phydev);
/* Determines the auto negotiation result */
int (*aneg_done)(struct phy_device *phydev);
/* Determines the negotiated speed and duplex */
int (*read_status)(struct phy_device *phydev);
/* Clears any pending interrupts */
int (*ack_interrupt)(struct phy_device *phydev);
/* Enables or disables interrupts */
int (*config_intr)(struct phy_device *phydev);
/*
* Checks if the PHY generated an interrupt. For multi-PHY devices with shared PHY
* interrupt pin. Set interrupt bits have to be cleared.
*/
int (*did_interrupt)(struct phy_device *phydev);
/* Override default interrupt handling */
int (*handle_interrupt)(struct phy_device *phydev);
/* Clears up any memory if needed */
void (*remove)(struct phy_device *phydev);
/* Returns true if this is a suitable driver for the given phydev.
If NULL, matching is based on phy_id and phy_id_mask.
*/
int (*match_phy_device)(struct phy_device *phydev);
/* Some devices (e.g. qnap TS-119P II) require PHY register changes to
* enable Wake on LAN, so set_wol is provided to be called in the
* ethernet driver's set_wol function.
*/
int (*set_wol)(struct phy_device *dev, struct ethtool_wolinfo *wol);
/* See set_wol, but for checking whether Wake on LAN is enabled. */
void (*get_wol)(struct phy_device *dev, struct ethtool_wolinfo *wol);
/*
* Called to inform a PHY device driver when the core is about to
* change the link state. This callback is supposed to be used as
* fixup hook for drivers that need to take action when the link
* state changes. Drivers are by no means allowed to mess with the
* PHY device structure in their implementations.
*/
void (*link_change_notify)(struct phy_device *dev);
/*
* Phy specific driver override for reading a MMD register.
* This function is optional for PHY specific drivers. When
* not provided, the default MMD read function will be used
* by phy_read_mmd(), which will use either a direct read for
* Clause 45 PHYs or an indirect read for Clause 22 PHYs.
* devnum is the MMD device number within the PHY device,
* regnum is the register within the selected MMD device.
*/
int (*read_mmd)(struct phy_device *dev, int devnum, u16 regnum);
/*
* Phy specific driver override for writing a MMD register.
* This function is optional for PHY specific drivers. When
* not provided, the default MMD write function will be used
* by phy_write_mmd(), which will use either a direct write for
* Clause 45 PHYs, or an indirect write for Clause 22 PHYs.
* devnum is the MMD device number within the PHY device,
* regnum is the register within the selected MMD device.
* val is the value to be written.
*/
int (*write_mmd)(struct phy_device *dev, int devnum, u16 regnum,
u16 val);
int (*read_page)(struct phy_device *dev);
int (*write_page)(struct phy_device *dev, int page);
/* Get the size and type of the eeprom contained within a plug-in
* module */
int (*module_info)(struct phy_device *dev,
struct ethtool_modinfo *modinfo);
/* Get the eeprom information from the plug-in module */
int (*module_eeprom)(struct phy_device *dev,
struct ethtool_eeprom *ee, u8 *data);
/* Get statistics from the phy using ethtool */
int (*get_sset_count)(struct phy_device *dev);
void (*get_strings)(struct phy_device *dev, u8 *data);
void (*get_stats)(struct phy_device *dev,
struct ethtool_stats *stats, u64 *data);
/* Get and Set PHY tunables */
int (*get_tunable)(struct phy_device *dev,
struct ethtool_tunable *tuna, void *data);
int (*set_tunable)(struct phy_device *dev,
struct ethtool_tunable *tuna,
const void *data);
int (*set_loopback)(struct phy_device *dev, bool enable);
};
其中,僅config_aneg 和 read_status 一定要寫,其餘都是Option的。另外,如果可能的話,最好使用這兩個函數的通用 PHY Driver ( genphy_read_status() 和 genphy_config_aneg()。
如果無法做到這一點,則可能只需要在調用這些函數之前和之後執行一些操作,因此您的函數將包裝通用函數。
/net /phy/目錄當中,有一堆已經寫好的例子,基本上已將涵蓋市面上的主流產品。
PHY的MMD暫存器訪問,在預設情況下由PAL框架處理,但是如果需要,可以由特定的PHY驅動程式取代。事實上MMD PHY暫存器的定義已經由IEEE加以標準化準化了。
板子硬體的配合修復程序
有時後,主晶片與與PHY之間由些特殊狀況需要處理。
例如,更改PHY時鐘輸入的位置,或添加延遲以解決數據路徑中的延遲問題。為了支持這種意外情況,PHY層允許平台代碼註冊在啟動PHY (或隨後重置)時運行的修補程序。
當PHY層啟動PHY時,它會檢查是否有為其註冊的修復程序,基於UID(包含在PHY設備的phy_id字段中)和總線標識符(包含在phydev-> dev.bus_id中)進行匹配。兩者必須匹配,但是兩個常量PHY_ANY_ID和PHY_ANY_UID作為通配符分別提供給總線ID和UID。
找到匹配項後,PHY層將調用與修復程序關聯的運行功能。該函數被傳遞一個指向感興趣的phy_device的指針。因此,它應僅在該PHY上運行。
平台代碼可以使用以下方法註冊修正phy_register_fixup():
int phy_register_fixup(const char *phy_id,
u32 phy_uid, u32 phy_uid_mask,
int (*run)(struct phy_device *));
或使用以下兩個Register之一:phy_register_fixup_for_uid()和phy_register_fixup_for_id();
int phy_register_fixup_for_uid (u32 phy_uid, u32 phy_uid_mask,
int (*run)(struct phy_device *));
int phy_register_fixup_for_id (const char *phy_id,
int (*run)(struct phy_device *));
Register設置兩個匹配條件之一,並設置另一個匹配任何條件。
當phy_register_fixup()在Module加載時,調用 phy_register_fixup_for_uid() / phy_register_fixup_for_id()時,Module需要取消註冊修正,並在卸載時釋放已分配的記憶體。
在卸載Module之前,會調用以下功能之一:
int phy_unregister_fixup(const char *phy_id, u32 phy_uid, u32 phy_uid_mask);
int phy_unregister_fixup_for_uid(u32 phy_uid, u32 phy_uid_mask);
int phy_register_fixup_for_id(const char *phy_id);
大多數網路裝置包含MAC與PHY,MAC透過一組暫存器與系統連接,MAC層通過PHY與網路的實體層連接進行通信。
PHY負責與Ethernet連接,並提供暫存器接口以允許Linux驅動程式來查詢網路的設置。PHY通常是一顆晶片,系統存取他的方式是透過MDIO BUS。下面先看一下MDIO BUS的驅動方式:
MDIO BUS
系統也許會有兩個以上的PHY,所以會有不同的MDIO BUS來連接PHY。
1. MDIO BUS必須要有的基本讀寫功能:
int write(struct mii_bus *bus, int mii_id, int regnum, u16 value);
int read(struct mii_bus *bus, int mii_id, int regnum);
mii_id是PHY BUS的地址,regnum 是暫存器編號。這兩個API都必須保證,系統處理中斷的時間,不會調用這些函數,因此要安全地BLOCK它們,等待中斷完成之後,才會被調用。
2. RESET功能是可選的。這用於使NUS回到初始化的狀態。
3. Probe功能是必要的。這函數應設置BUS驅動程序所需的任何資料結構,設定 mii_bus 資料結構,並使用 mdiobus_register向PAL註冊。同樣,mdiobus_unregister可以註銷所有功能(使用)。
4. 像任何驅動程序一樣,必須配置device_driver資料結構,並使用init exit 來註冊驅動程序。
5. BUS也必須在某處宣告為設備,並進行註冊。
mdio bus driver 範例位於 drivers/net/phy/realtek.c
RGMII 電氣特性注意事項:
RGMII 是12針的電信號接口,使用同步125 MHz 時鐘信號和幾條數據線。由於此設計決定,必須在Clock 時鐘線 (RXC 或TXC )和Data Lines 之間添加 1.5ns 至 2ns 的延遲,以使PHY(時鐘接收器)具有足夠大的建立和保持時間以正確採樣 Data Lines。
PHY Library 提供了不同類型的PHY_INTERFACE_MODE_RGMII 值,以使PHY驅動程序以及可選的MAC驅動程序實現所需的延遲。必須從PHY設備本身的角度理解 phy_interface_t 的值,這導致:
PHY_INTERFACE_MODE_RGMII:PHY本身不負責插入任何內部延遲,它假設Ethernet MAC或PCB走線會插入正確的 1.5-2 ns 延遲。
PHY_INTERFACE_MODE_RGMII_TXID:PHY應該為PHY設備處理的發送數據線(TXD [3:0])插入內部延遲。
PHY_INTERFACE_MODE_RGMII_RXID:PHY應該為由PHY設備處理的接收數據線(RXD [3:0])插入內部延遲。
PHY_INTERFACE_MODE_RGMII_ID:PHY應該為來自/去往PHY設備的發送和接收數據線插入內部延遲
出於以下原因,請盡可能使用PHY端RGMII延遲:
1. PHY可以提供 sub-nanosecond 等級的延遲(例如:0.5、1.0、1.5ns)。如果使用PCB走線,因為長度的差異,可能能以達到這種精度。
2. PHY設備可以在溫度/壓力/電壓範圍內提供恆定且可靠的延遲。
PHYLIB中的PHY設備驅動程序本質上是可重用的,能夠正確配置指定的延遲,從而使更多具有類似延遲要求的設計能夠正確運行
對於PHY無法提供此延遲但以太網MAC驅動程序能夠提供此延遲的情況,正確的phy_interface_t值應為PHY_INTERFACE_MODE_RGMII,並且應正確配置以太網MAC驅動程序以提供所需的發送和/或從PHY設備的角度接收側延遲。相反,如果以太網MAC驅動程序查看phy_interface_t值,則對於除PHY_INTERFACE_MODE_RGMII之外的任何其他模式,都應確保禁用了MAC級延遲。
如果按照RGMII標准定義,以太網MAC和PHY均不能提供所需的延遲,則可能有幾種選擇:
某些SoC可能會提供一個引腳墊/多路復用器/控制器,能夠配置一組給定的引腳強度,延遲和電壓。並且插入預期的2ns RGMII延遲可能是合適的選擇。
修改PCB設計以包括固定的延遲(例如:使用專門設計的蛇形),這可能根本不需要軟件配置。
與RGMII延遲失配的常見問題
當以太網MAC和PHY之間存在RGMII延遲不匹配時,當PHY或MAC對這些信號進行快照以將它們轉換為邏輯1或0狀態時,這很可能導致時鐘和數據線信號不穩定並重建正在發送/接收的數據。典型症狀包括:
傳輸/接收部分起作用,並且觀察到頻繁或偶發的數據包丟失。
以太網MAC可能報告一些或所有進入FCS / CRC錯誤的數據包,或者只是丟棄所有這些數據包。
切換到較低的速度(例如10 / 100Mbits /秒)可以解決問題(因為在這種情況下有足夠的建立/保持時間)。
連接到在啟動過程中的某個時候,網路驅動程序需要在PHY設備和網路設備之間建立連接。這時,PHY的總線和驅動程序都已加載完畢,因此可以進行連接了。此時,有幾種方法可以連接到PHY:
- PHY處理所有事情,並且僅在鏈接狀態更改時才調用網路驅動程序,因此它可以做出反應。
- PHY處理除中斷外的所有內容(通常是因為控制器具有中斷暫存器)。
- PHY處理所有事情,但每秒檢查一次驅動程序,從而允許網路驅動程序在PAL之前先對所有更改做出反應。
- PHY僅用做為功能庫,網路設備手動調用功能以更新狀態並配置PHY
讓PHY抽象層做所有事情
如果選擇選項1(希望每個驅動程序都可以,但對於不能驅動的驅動程序仍然有用),則連接到PHY很簡單:
首先,您需要一個函數來響應鏈接狀態的變化。此功能遵循以下協議:
static void adjust_link(struct net_device *dev);
接下來,您需要知道連接到該設備的PHY的設備名稱。名稱將看起來像“ 0:00”,其中第一個數字是總線ID,第二個數字是該總線上PHY的地址。通常,總線負責使其ID唯一。
現在,要連接,只需調用此函數:
phydev = phy_connect(dev, phy_name, &adjust_link, interface);
phydev是指向表示PHY的phy_device結構的指針。如果phy_connect成功,它將返回指針。dev在這裡是指向net_device的指針。一旦完成,該功能將啟動PHY的軟件狀態機,並為PHY的中斷註冊(如果有)。PHYdev結構將填充有關當前狀態的信息,儘管此時PHY尚未真正運行。
在調用之前,應在phydev-> dev_flags中設置PHY特定的標誌phy_connect(),以便底層PHY驅動程式可以檢查標誌並基於它們執行特定的操作。如果系統對PHY /控制器施加了硬件限制,而PHY需要了解這些限制,則這將很有用。
接口是一個u32,它指定控制器和PHY之間使用的連接類型。實例是GMII,MII,RGMII和SGMII。請參見下面的“ PHY接口模式”。有關完整列表,請參見include / linux / phy.h
現在只需確保phydev-> supported和phydev-> advertising都從它們中刪除了對您的控制器沒有意義的任何值 (10/100控制器可能已連接到具有千兆位功能的PHY,因此您需要屏蔽關閉SUPPORTED_1000baseT *)。
有關這些位域的定義,請參見 include / linux / ethtool.h。請注意,除了SUPPORTED_Pause和SUPPORTED_AsymPause位(請參見下文)外,您不應該設置任何位,否則PHY可能會進入不受支持的狀態。
最後,一旦控制器準備好處理網路流量,就可以調用phy_start(phydev)。這告訴PAL您已準備就緒,並配置PHY以連接到網路。如果網路驅動程式的MAC中斷也處理PHY狀態更改,則只需在將phydev-> irq設置為PHY_IGNORE_INTERRUPT,然後再phy_mac_interrupt()從網路驅動程式調用phy_start並使用它即可。如果不想使用中斷,請將phydev-> irq設置為PHY_POLL。 phy_start()啟用PHY中斷(如果適用)並啟動phylib狀態機。
如果要斷開網路連接(即使只是短暫斷開連接),請調用 phy_stop(phydev)。此功能還可以停止phylib狀態機並禁用PHY中斷。
PHY接口模式
phy_connect()功能係列中提供的PHY接口模式定義了PHY接口的初始操作模式。這不能保證保持恆定。有些PHY會根據協商結果動態更改其接口模式,而無需軟件交互。
一些接口模式如下所述:
PHY_INTERFACE_MODE_1000BASEX
這定義了802.3標準第36條所定義的1000BASE-X單通道Serdes鏈接。該鏈接使用10B / 8B編碼方案以1.25Gbaud的固定位速率運行,從而產生1Gbps的基礎數據速率。數據流中嵌入了一個16位控製字,用於與遠端協商雙工和暫停模式。這不包括“超頻”變體,例如2.5Gbps速度(請參閱下文)。
PHY_INTERFACE_MODE_2500BASEX
這定義了1000BASE-X的變體,其時鐘頻率比802.3標準快2.5倍,後者提供了3.125Gbaud的固定比特率。
PHY_INTERFACE_MODE_SGMII
這用於Cisco SGMII,它是對802.3標准定義的1000BASE-X的修改。SGMII鏈路由一條串行SERDES通道組成,該通道以1.25Gbaud的固定比特率運行,具有10B / 8B編碼。基本數據速率為1Gbps,通過複製每個數據符號可實現100Mbps和10Mbps的較慢速度。802.3控製字的用途是重新發送協商的速度和雙工信息到MAC,並讓MAC確認接收。這不包括“超頻”變體,例如2.5Gbps速度。
注意:在某些情況下,鏈路上的SGMII與1000BASE-X配置不匹配可以成功傳遞數據,但是16位控製字將無法正確解釋,這可能導致雙工,暫停或其他設置不匹配。這取決於MAC和/或PHY行為。
PHY_INTERFACE_MODE_10GBASER
這是IEEE 802.3條款49定義的10GBASE-R協議,可用於各種不同的介質。有關此定義,請參考IEEE標準。
注意:10GBASE-R只是可以與XFI和SFI一起使用的一種協議。XFI和SFI允許在單個SERDES通道上使用多種協議,並且通過將主機兼容板插入主機XFP / SFP連接器來定義信號的電氣特性。因此,XFI和SFI本身並不是PHY接口類型。
PHY_INTERFACE_MODE_10GKR
這是IEEE 802.3條款49定義的帶有條款73自動協商的10GBASE-R。請參考IEEE標準以獲取更多信息。
暫停Bit/流量控制
PHY不會直接參與流控制/暫停Bit,除非確保在MII_ADVERTISE中將SUPPORTED_Pause和SUPPORTED_AsymPause位設置為向鏈路夥伴,表明以太網MAC控制器支持這種情況。由於流控制/暫停幀的生成涉及以太網MAC驅動程式,因此建議該驅動程式通過相應地設置SUPPORTED_Pause和SUPPORTED_AsymPause位來適當地指示廣告和對此類功能的支持。可以在 phy_connect() 實現 ethtool :: set_pauseparam功能之前或之後和/或作為結果。
在PAL上保持關閉選項卡
PAL的內置狀態機可能需要一點幫助,以使您的網路設備和PHY正確同步。如果是這樣,您可以在連接到PHY時註冊一個輔助函數,該函數將在狀態機對任何更改做出反應之前每秒調用一次。為此,您需要手動調用phy_attach()和phy_prepare_link(),然後phy_start_machine()在第二個參數設置為指向您的特殊處理程序的情況下進行調用 。
當前尚無有關如何使用此功能的示例,並且由於作者沒有使用該功能的驅動程式(它們全部使用選項1),因此對其進行的測試受到限制。因此,警告皇帝。
自己動手做
PAL的內置狀態機極有可能無法跟踪PHY與您的網路設備之間的複雜交互。如果是這樣,您可以直接調用phy_attach(),而不能調用phy_start_machine或 phy_prepare_link()。這將意味著phydev-> state完全由您處理(phy_start和phy_stop在某些狀態之間切換,因此您可能需要避免它們)。
已經做出努力以確保可以在不運行狀態機的情況下訪問有用的功能,並且這些功能中的大多數是未與復雜狀態機交互的功能的後繼功能。但是,到目前為止,在沒有狀態機的情況下,到目前為止尚未做出任何努力來測試運行情況,因此請謹慎嘗試。
以下是這些功能的簡要概述:
int phy_read(struct phy_device *phydev, u16 regnum);
int phy_write(struct phy_device *phydev, u16 regnum, u16 val);
簡單的讀/寫原語。它們調用總線的讀/寫功能指針。
void phy_print_status(struct phy_device *phydev);
方便的功能可以整齊地打印PHY狀態。
void phy_request_interrupt(struct phy_device *phydev);
請求PHY中斷的IRQ。
struct phy_device * phy_attach(struct net_device *dev, const char *phy_id,
phy_interface_t interface);
將網路設備連接到特定的PHY,如果在總線初始化期間未找到PHY,則將PHY綁定到通用驅動程式。
int phy_start_aneg(struct phy_device *phydev);
使用phydev結構內部的變量,可以配置廣告並重置自動協商,或者禁用自動協商並配置強制設置。
static inline int phy_read_status(struct phy_device *phydev);
用有關PHY中當前設置的最新信息填充phydev結構。
int phy_ethtool_ksettings_set(struct phy_device *phydev,
const struct ethtool_link_ksettings *cmd);
Ethtool便利功能。
int phy_mii_ioctl(struct phy_device *phydev,
struct mii_ioctl_data *mii_data, int cmd);
MII ioctl。請注意,如果您寫入諸如BMCR,BMSR,ADVERTISE等暫存器,則此功能將完全破壞狀態機。最好僅使用此功能來寫入非標準的暫存器,並且不要啟動重新協商。
PHY Device Driver (設備驅動程序)
借助PHY抽象層,添加對新PHY的支持非常容易。有時候,根本沒有工作要做。
Generic PHY driver
這是最常用的驅動程式。
編寫PHY驅動程式
如果確實需要編寫PHY驅動程式,可以參考一下的說明。
首先要在BUS初始化的時候,先讀取裝置的UID (儲存在暫存器2和3之中),然後通過將其與每個驅動程式的 phy_id 字段與每個驅動程式的phy_id_mask字段,進行“與”操作進行比較來完成的。另外,它需要一個名稱。以下是一個例子:
static struct phy_driver dm9161_driver = {
.phy_id = 0x0181b880,
.name = "Davicom DM9161E",
.phy_id_mask = 0x0ffffff0,
...
}
接下來,您需要指定PHY設備和驅動程式支持哪些功能 ( speed, duplex, autoreg )。大多數PHY支持 PHY_BASIC_FEATURES,但是您可以在 #include/mii.h中查找其他功能。
每個驅動程式由許多函數 pointer 組成,這些point定義於 #include/linux/phy.h 檔案中struct phy_driver。
/*
struct phy_driver: Driver structure for a particular PHY type driver_data: static driver data
phy_id: The result of reading the UID registers of this PHY type, and ANDing them with the phy_id_mask. This driver only works for PHYs with IDs which match this field name: The friendly name of this PHY type phy_id_mask: Defines the important bits of the phy_id features:
A mandatory list of features (speed, duplex, etc) supported by this PHY flags: A bitfield defining certain other features this PHY supports (like interrupts)
All functions are optional. If config_aneg or read_status are not implemented, the phy core uses the genphy versions. Note that none of these functions should be called from interrupt time. The goal is for the bus read/write functions to be able to block when the bus transaction is happening, and be freed up by an interrupt (The MPC85xx has this ability, though it is not currently supported in the driver).
*/
struct phy_driver {
struct mdio_driver_common mdiodrv;
u32 phy_id;
char *name;
u32 phy_id_mask;
const unsigned long * const features;
u32 flags;
const void *driver_data;
/*
* Called to issue a PHY software reset
*/
int (*soft_reset)(struct phy_device *phydev);
/*
* Called to initialize the PHY, including after a reset
*/
int (*config_init)(struct phy_device *phydev);
/*
* Called during discovery. Used to set up device-specific structures, if any
*/
int (*probe)(struct phy_device *phydev);
/*
* Probe the hardware to determine what abilities it has. Should only set phydev->supported.
*/
int (*get_features)(struct phy_device *phydev);
/* PHY Power Management */
int (*suspend)(struct phy_device *phydev);
int (*resume)(struct phy_device *phydev);
/*
* Configures the advertisement and resets autonegotiation if phydev->autoneg is on,
* forces the speed to the current settings in phydev, if phydev->autoneg is off
*/
int (*config_aneg)(struct phy_device *phydev);
/* Determines the auto negotiation result */
int (*aneg_done)(struct phy_device *phydev);
/* Determines the negotiated speed and duplex */
int (*read_status)(struct phy_device *phydev);
/* Clears any pending interrupts */
int (*ack_interrupt)(struct phy_device *phydev);
/* Enables or disables interrupts */
int (*config_intr)(struct phy_device *phydev);
/*
* Checks if the PHY generated an interrupt. For multi-PHY devices with shared PHY
* interrupt pin. Set interrupt bits have to be cleared.
*/
int (*did_interrupt)(struct phy_device *phydev);
/* Override default interrupt handling */
int (*handle_interrupt)(struct phy_device *phydev);
/* Clears up any memory if needed */
void (*remove)(struct phy_device *phydev);
/* Returns true if this is a suitable driver for the given phydev.
If NULL, matching is based on phy_id and phy_id_mask.
*/
int (*match_phy_device)(struct phy_device *phydev);
/* Some devices (e.g. qnap TS-119P II) require PHY register changes to
* enable Wake on LAN, so set_wol is provided to be called in the
* ethernet driver's set_wol function.
*/
int (*set_wol)(struct phy_device *dev, struct ethtool_wolinfo *wol);
/* See set_wol, but for checking whether Wake on LAN is enabled. */
void (*get_wol)(struct phy_device *dev, struct ethtool_wolinfo *wol);
/*
* Called to inform a PHY device driver when the core is about to
* change the link state. This callback is supposed to be used as
* fixup hook for drivers that need to take action when the link
* state changes. Drivers are by no means allowed to mess with the
* PHY device structure in their implementations.
*/
void (*link_change_notify)(struct phy_device *dev);
/*
* Phy specific driver override for reading a MMD register.
* This function is optional for PHY specific drivers. When
* not provided, the default MMD read function will be used
* by phy_read_mmd(), which will use either a direct read for
* Clause 45 PHYs or an indirect read for Clause 22 PHYs.
* devnum is the MMD device number within the PHY device,
* regnum is the register within the selected MMD device.
*/
int (*read_mmd)(struct phy_device *dev, int devnum, u16 regnum);
/*
* Phy specific driver override for writing a MMD register.
* This function is optional for PHY specific drivers. When
* not provided, the default MMD write function will be used
* by phy_write_mmd(), which will use either a direct write for
* Clause 45 PHYs, or an indirect write for Clause 22 PHYs.
* devnum is the MMD device number within the PHY device,
* regnum is the register within the selected MMD device.
* val is the value to be written.
*/
int (*write_mmd)(struct phy_device *dev, int devnum, u16 regnum,
u16 val);
int (*read_page)(struct phy_device *dev);
int (*write_page)(struct phy_device *dev, int page);
/* Get the size and type of the eeprom contained within a plug-in
* module */
int (*module_info)(struct phy_device *dev,
struct ethtool_modinfo *modinfo);
/* Get the eeprom information from the plug-in module */
int (*module_eeprom)(struct phy_device *dev,
struct ethtool_eeprom *ee, u8 *data);
/* Get statistics from the phy using ethtool */
int (*get_sset_count)(struct phy_device *dev);
void (*get_strings)(struct phy_device *dev, u8 *data);
void (*get_stats)(struct phy_device *dev,
struct ethtool_stats *stats, u64 *data);
/* Get and Set PHY tunables */
int (*get_tunable)(struct phy_device *dev,
struct ethtool_tunable *tuna, void *data);
int (*set_tunable)(struct phy_device *dev,
struct ethtool_tunable *tuna,
const void *data);
int (*set_loopback)(struct phy_device *dev, bool enable);
};
其中,僅config_aneg 和 read_status 一定要寫,其餘都是Option的。另外,如果可能的話,最好使用這兩個函數的通用 PHY Driver ( genphy_read_status() 和 genphy_config_aneg()。
如果無法做到這一點,則可能只需要在調用這些函數之前和之後執行一些操作,因此您的函數將包裝通用函數。
/net /phy/目錄當中,有一堆已經寫好的例子,基本上已將涵蓋市面上的主流產品。
PHY的MMD暫存器訪問,在預設情況下由PAL框架處理,但是如果需要,可以由特定的PHY驅動程式取代。事實上MMD PHY暫存器的定義已經由IEEE加以標準化準化了。
板子硬體的配合修復程序
有時後,主晶片與與PHY之間由些特殊狀況需要處理。
例如,更改PHY時鐘輸入的位置,或添加延遲以解決數據路徑中的延遲問題。為了支持這種意外情況,PHY層允許平台代碼註冊在啟動PHY (或隨後重置)時運行的修補程序。
當PHY層啟動PHY時,它會檢查是否有為其註冊的修復程序,基於UID(包含在PHY設備的phy_id字段中)和總線標識符(包含在phydev-> dev.bus_id中)進行匹配。兩者必須匹配,但是兩個常量PHY_ANY_ID和PHY_ANY_UID作為通配符分別提供給總線ID和UID。
找到匹配項後,PHY層將調用與修復程序關聯的運行功能。該函數被傳遞一個指向感興趣的phy_device的指針。因此,它應僅在該PHY上運行。
平台代碼可以使用以下方法註冊修正phy_register_fixup():
int phy_register_fixup(const char *phy_id,
u32 phy_uid, u32 phy_uid_mask,
int (*run)(struct phy_device *));
或使用以下兩個Register之一:phy_register_fixup_for_uid()和phy_register_fixup_for_id();
int phy_register_fixup_for_uid (u32 phy_uid, u32 phy_uid_mask,
int (*run)(struct phy_device *));
int phy_register_fixup_for_id (const char *phy_id,
int (*run)(struct phy_device *));
Register設置兩個匹配條件之一,並設置另一個匹配任何條件。
當phy_register_fixup()在Module加載時,調用 phy_register_fixup_for_uid() / phy_register_fixup_for_id()時,Module需要取消註冊修正,並在卸載時釋放已分配的記憶體。
在卸載Module之前,會調用以下功能之一:
int phy_unregister_fixup(const char *phy_id, u32 phy_uid, u32 phy_uid_mask);
int phy_unregister_fixup_for_uid(u32 phy_uid, u32 phy_uid_mask);
int phy_register_fixup_for_id(const char *phy_id);
2020年5月11日 星期一
如何啟動Bluetooth 模組 ?
每次想要做點小事,就會出現一堆不相干的問題,然後就要讀一堆東西,之後又忘記原先想要做的事情。
這次的題目是延續之前的問題? 如何開關Bluetooth模組? 這個動作就是我們搭飛機的時候,空姐會在起飛的時候要我們關掉藍芽,也就是進飛航模式。前面那篇已經測試過了,hciconfig up/down 是關不掉BT模組的。
問題很小,但衍伸的討論卻不小。先講如何打開好了。命令簡單,
# systemctl start bluetooth.service
# systemctl status bluetooth.service
這組命令,改試 rfkill
root@luke-G50:/home/dang# rfkill list
0: ideapad_wlan: Wireless LAN
Soft blocked: no
Hard blocked: no
1: ideapad_bluetooth: Bluetooth
Soft blocked: no
Hard blocked: no
2: phy0: Wireless LAN
Soft blocked: no
Hard blocked: no
如果想要關掉Bluetooth,可以
# rfkill unblock bluetooth <Enter>
# rfkill list <Enter>
0: ideapad_wlan: Wireless LAN
Soft blocked: no
Hard blocked: no
1: ideapad_bluetooth: Bluetooth
Soft blocked: yes
Hard blocked: no
2: phy0: Wireless LAN
Soft blocked: no
Hard blocked: no
這次的題目是延續之前的問題? 如何開關Bluetooth模組? 這個動作就是我們搭飛機的時候,空姐會在起飛的時候要我們關掉藍芽,也就是進飛航模式。前面那篇已經測試過了,hciconfig up/down 是關不掉BT模組的。
問題很小,但衍伸的討論卻不小。先講如何打開好了。命令簡單,
# systemctl enable bluetooth.service
# systemctl start bluetooth.service
# systemctl status bluetooth.service
第一行命令敲下去
# systemctl enable bluetooth.service <Enter>
# systemctl: command not found
連忙
# ps -ef | grep systemd <Enter>
root 24009 1 0 5月03 ? 00:00:00 /lib/systemd/systemd-udevd --daemon
root 27526 1 0 5月03 ? 00:00:00 /lib/systemd/systemd-logind
誰知道系統之中明明有 systemd 再跑,但沒有 systemctl,於是只好多作好幾步;
# sudo apt-get install -reinstall systemd <Enter>
一串訊息之後,終於重新裝好了 systmed。想問甚麼是 systemd ? 簡單說,就是 Windows/Android之中,System Services的概念,細節就不談下去了。
忙了半天還不能RUN,後來才發現 systemd 要到 15.04 之後才能使用,但我的版本
# lsb_release -a <Enter>
發現 Ubuntu 14.04.6,所以Run起來似乎怪怪的。於是放棄
# # systemctl start bluetooth.service
# systemctl status bluetooth.service
這組命令,改試 rfkill
root@luke-G50:/home/dang# rfkill list
0: ideapad_wlan: Wireless LAN
Soft blocked: no
Hard blocked: no
1: ideapad_bluetooth: Bluetooth
Soft blocked: no
Hard blocked: no
2: phy0: Wireless LAN
Soft blocked: no
Hard blocked: no
如果想要關掉Bluetooth,可以
# rfkill unblock bluetooth <Enter>
# rfkill list <Enter>
0: ideapad_wlan: Wireless LAN
Soft blocked: no
Hard blocked: no
1: ideapad_bluetooth: Bluetooth
Soft blocked: yes
Hard blocked: no
2: phy0: Wireless LAN
Soft blocked: no
Hard blocked: no
關閉全部無線裝置可以用下列命令:
2020年5月9日 星期六
Open GL 研讀
想要實際看看OPEN GL的程式寫法的念頭,也有一段時間了,今日閒來無事,決定下海玩玩。先到Super User 看一下與OpenGL有關係的工具有哪些?

結果出現好幾頁的工具,看來有點複雜,決定還是由基礎開始。
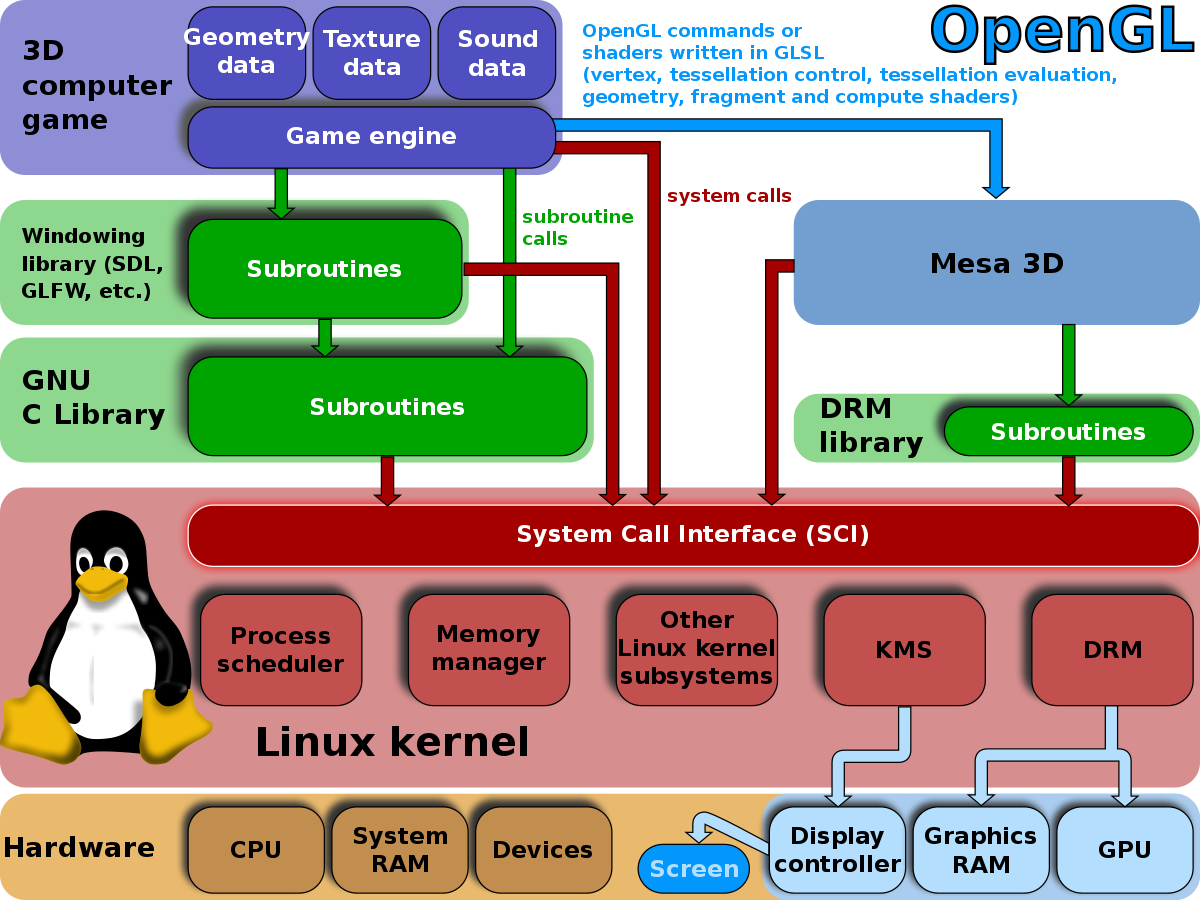
這是大致上的架構。
研究了這一堆的工具之後,決定選擇 FreeGLUT 作為開發的實驗平台。先下載工具:
root@luke-G50:/home/dang# apt-get install freeglut3 freeglut3-dev libglew-dev <Enter>
Reading package lists... Done
Building dependency tree
Reading state information... Done
freeglut3 is already the newest version.
freeglut3 set to manually installed.
The following packages were automatically installed and are no longer required:
libbonobo2-0 libbonobo2-common libdbusmenu-gtk4 libgconf2-4 libgnome2-0
libgnome2-bin libgnome2-common libgnomevfs2-0 libgnomevfs2-common
libidl-common libidl0 liborbit-2-0 liborbit2 libqpdf13
...
接下來還需要裝MESA開發工具:
root@luke-G50:/home/dang# apt-get install mesa-utils
root@luke-G50:/home/dang# mkdir 3D
root@luke-G50:/home/dang# cd 3D
root@luke-G50:/home/dang# vi example1.c
#include "GL/freeglut.h"
#include "GL/gl.h"
void drawSquare()
{
glClearColor(0.4, 0.4, 0.4, 0.4);
glClear(GL_COLOR_BUFFER_BIT);
glColor3f(1.0, 1.0, 1.0); /* 1.0, 1.0, 1.0 is white */
glOrtho(-1.0, 1.0, -1.0, 1.0, -1.0, 1.0);
glBegin(GL_SQUARE);
glVertex3f(-0.7, 0.7, 0);
glVertex3f(0.7, 0.7, 0);
glVertex3f(0, -1, 0);
glVertex3f(0, -1, 0);
glEnd();
glFlush();
}
int main(int argc, char **argv)
{
glutInit(&argc, argv);
glutInitDisplayMode(GLUT_SINGLE);
glutInitWindowSize(500, 500);
glutInitWindowPosition(100, 100);
glutCreateWindow("OpenGL - Creating a square");
glutDisplayFunc(drawSquare);
glutMainLoop();
return 0;
}
在OpenGL初始化完成之後,首先是設定要把圖畫到一個三維的區域之中,這裡glOrtho(left, right, bottom, top, near, far) 來做設定。
glOrtho()一般用於物體不會因為離螢幕的遠近而產生大小的變換的情況。反過來,在真實生活中,人們視野觀測物體的真實情況。例如:觀察兩條平行的火車到,在過了很遠之後,這兩條鐵軌是會相交於一處的。還有,離眼睛近的物體看起來大一些,遠的物體看起來小一些。這時候畫圖就要別的函數。
glOrtho(left, right, bottom, top, near, far), left表示視景體左面的座標,right表示右面的座標,bottom表示下面的,top表示上面的。這個函數簡單理解起來,就是一個物體擺在那裡,你怎麼去截取他。假設有一個方形立方體,圓心在(0, 0, 0),那麼,我們可以設定glOrtho(-1, 1, -1, 1, -10, 10)。
root@luke-G50:/home/dang/3D# cc example1.c -l glut -lGL -o tt <Enter>
然後回到X-Windows DEsktop之下,找到tt點下去。就看到了這個三角形。
結果出現好幾頁的工具,看來有點複雜,決定還是由基礎開始。
這是大致上的架構。
研究了這一堆的工具之後,決定選擇 FreeGLUT 作為開發的實驗平台。先下載工具:
root@luke-G50:/home/dang# apt-get install freeglut3 freeglut3-dev libglew-dev <Enter>
Reading package lists... Done
Building dependency tree
Reading state information... Done
freeglut3 is already the newest version.
freeglut3 set to manually installed.
The following packages were automatically installed and are no longer required:
libbonobo2-0 libbonobo2-common libdbusmenu-gtk4 libgconf2-4 libgnome2-0
libgnome2-bin libgnome2-common libgnomevfs2-0 libgnomevfs2-common
libidl-common libidl0 liborbit-2-0 liborbit2 libqpdf13
...
接下來還需要裝MESA開發工具:
root@luke-G50:/home/dang# apt-get install mesa-utils
root@luke-G50:/home/dang# mkdir 3D
root@luke-G50:/home/dang# cd 3D
root@luke-G50:/home/dang# vi example1.c
#include "GL/freeglut.h"
#include "GL/gl.h"
void drawSquare()
{
glClearColor(0.4, 0.4, 0.4, 0.4);
glClear(GL_COLOR_BUFFER_BIT);
glColor3f(1.0, 1.0, 1.0); /* 1.0, 1.0, 1.0 is white */
glOrtho(-1.0, 1.0, -1.0, 1.0, -1.0, 1.0);
glBegin(GL_SQUARE);
glVertex3f(-0.7, 0.7, 0);
glVertex3f(0.7, 0.7, 0);
glVertex3f(0, -1, 0);
glVertex3f(0, -1, 0);
glEnd();
glFlush();
}
int main(int argc, char **argv)
{
glutInit(&argc, argv);
glutInitDisplayMode(GLUT_SINGLE);
glutInitWindowSize(500, 500);
glutInitWindowPosition(100, 100);
glutCreateWindow("OpenGL - Creating a square");
glutDisplayFunc(drawSquare);
glutMainLoop();
return 0;
}
在OpenGL初始化完成之後,首先是設定要把圖畫到一個三維的區域之中,這裡glOrtho(left, right, bottom, top, near, far) 來做設定。
glOrtho()一般用於物體不會因為離螢幕的遠近而產生大小的變換的情況。反過來,在真實生活中,人們視野觀測物體的真實情況。例如:觀察兩條平行的火車到,在過了很遠之後,這兩條鐵軌是會相交於一處的。還有,離眼睛近的物體看起來大一些,遠的物體看起來小一些。這時候畫圖就要別的函數。
glOrtho(left, right, bottom, top, near, far), left表示視景體左面的座標,right表示右面的座標,bottom表示下面的,top表示上面的。這個函數簡單理解起來,就是一個物體擺在那裡,你怎麼去截取他。假設有一個方形立方體,圓心在(0, 0, 0),那麼,我們可以設定glOrtho(-1, 1, -1, 1, -10, 10)。
root@luke-G50:/home/dang/3D# cc example1.c -l glut -lGL -o tt <Enter>
然後回到X-Windows DEsktop之下,找到tt點下去。就看到了這個三角形。
2020年5月3日 星期日
Linux Kernel Module 的操作指令
這紀錄是用Ubuntu系統來說的,我用的版本是4.2.0-42
1. 列出目前Kernel當中所有的模組
# lsmod <Enter>
2. 想要了解一下某一個驅動或模組的相關資訊
# modinfor module_name
例如想知道一下Bluetooth驅動的狀況
資訊不少。
$ systool -v -m module_name <Enter>
也可以看到整理得更為完整的資訊。
3. 顯示模組/驅動的的相關性:
4. 對於模組的操作
4.1 Load a module
# modprobe module_name <Enter>
4.2 Load a module by filename
# insmod file_name <Enter>
4.3 Unload a module
# modprobe -r module_name <Enter>
或
# rmmod module_name <Enter>
5. 對模組傳遞參數
# modprobe module_name parameter_name=parameter_value <Enter>
root@luke-G50:/etc/bluetooth# uname -a <Enter>
Linux luke-G50 4.2.0-42-generic #49~14.04.1-Ubuntu SMP Wed Jun 29 20:22:11 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
1. 列出目前Kernel當中所有的模組
# lsmod <Enter>
2. 想要了解一下某一個驅動或模組的相關資訊
# modinfor module_name
例如想知道一下Bluetooth驅動的狀況
root@luke-G50:/etc/bluetooth# modinfo btusb <Enter>
filename: /lib/modules/4.2.0-42-generic/kernel/drivers/bluetooth/btusb.ko
license: GPL
version: 0.8
description: Generic Bluetooth USB driver ver 0.8
author: Marcel Holtmann <marcel@holtmann.org>
srcversion: 0F5AD5777734F86F537134A
alias: usb:v8087p0A5Ad*dc*dsc*dp*ic*isc*ip*in*
...
alias: usb:v04CAp*d*dc*dsc*dp*icFFisc01ip01in*
alias: usb:v*p*d*dcE0dsc01dp01ic*isc*ip*in*
depends: bluetooth,btrtl,btintel,btbcm
intree: Y
vermagic: 4.2.0-42-generic SMP mod_unload modversions
signer: Build time autogenerated kernel key
sig_key: E1:78:61:78:9C:2D:8F:1B:8F:C3:6C:CA:1B:40:2A:6D:F7:B7:EE:A8
sig_hashalgo: sha512
parm: disable_scofix:Disable fixup of wrong SCO buffer size (bool)
parm: force_scofix:Force fixup of wrong SCO buffers size (bool)
parm: reset:Send HCI reset command on initialization (bool)
資訊不少。
$ systool -v -m module_name <Enter>
也可以看到整理得更為完整的資訊。
3. 顯示模組/驅動的的相關性:
root@luke-G50:/etc/bluetooth# modprobe --show-depends btusb <Enter>
insmod /lib/modules/4.2.0-42-generic/kernel/net/bluetooth/bluetooth.ko
insmod /lib/modules/4.2.0-42-generic/kernel/drivers/bluetooth/btintel.ko
insmod /lib/modules/4.2.0-42-generic/kernel/drivers/bluetooth/btbcm.ko
insmod /lib/modules/4.2.0-42-generic/kernel/drivers/bluetooth/btrtl.ko
insmod /lib/modules/4.2.0-42-generic/kernel/drivers/bluetooth/btusb.ko
4. 對於模組的操作
4.1 Load a module
# modprobe module_name <Enter>
4.2 Load a module by filename
# insmod file_name <Enter>
4.3 Unload a module
# modprobe -r module_name <Enter>
或
# rmmod module_name <Enter>
5. 對模組傳遞參數
# modprobe module_name parameter_name=parameter_value <Enter>
2020年5月2日 星期六
BlueZ 的研讀紀錄(二): Device在哪裡 ?
由於沒有找到Device Name,依照我的習慣,先找找那些檔案是相關與Bluetooth的。
結果找到:
HCI這個名詞常常出現在Bluetooth的命令之中,所以先了解一下。
Bluetooth 基本上可以大致分為底層硬體的PHY (就是我們平常說的BT4.1, BT5.0) 與上層的應用Profile,目前已經有一堆Profile被定義:
1 A2DP : 藍牙立體聲音訊傳輸規範(Advanced Audio Distribution Profile )
2 ATT:(Attribute Profile)
3 AVRCP:音訊/影片遠端控制設定檔(Audio/Video Remote Control Profile)
4 BIP:基本圖像規範(Basic Imaging Profile)
5 BPP:基本列印規範(Basic Printing Profile)
6 CIP:ISDN規範(Common ISDN Access Profile)
7 CTP:無線電話規範(Cordless Telephony Profile)
8 DIP:裝置識別符號規範(Device ID Profile)
9 DUN:撥接網路規範(Dial-up Networking Profile)
10 FAX:傳真規範(Fax Profile)
11 FTP:檔案傳輸規範(File Transfer Profile)
12 GAVDP:影音傳送通用規範(Generic Audio/Video Distribution Profile)
13 GAP:通用存取規範(Generic Access Profile) – BLE 相關規範。
14 GATT:通用型連接規範(Generic Attribute Profile) – BLE 相關規範。
15 Generic Object Exchange Profile (GOEP)
16 Hard Copy Cable Replacement Profile (HCRP)
17 HDP:醫療設備規範(Health Device Profile )
18 HFP:手持裝置規範(Hands-Free Profile )
19 HID:人機介面規範(Human Interface Device Profile)
20 Headset Profile (HSP)
21 ICP:網內通訊規範(Intercom Profile )
22 LAP:網路訪問配置規範(LAN Access Profile)
23 MESH:MESH規範(Mesh Profile)
24 MAP:簡訊交換規範(Message Access Profile)
25 OBEX:泛用物件交換規範(OBject EXchange)
26 OPP:物件交換規範(Object Push Profile)
27 PAN:個人區域網路規範(Personal Area Networking Profile)
28 PBAP:電話簿存取規範(Phone Book Access Profile)
29 PXP:裝置接近規範(Proximity Profile)
30 SPP:序列埠規範(Serial Port Profile)
31 SDAP:服務搜尋規範(Service Discovery Application Profile)
32 SIM:SIM卡的遠端存取規範(SIM Access Profile, SAP, SIM or rSAP)
33 SYNCH:資訊同步規範(Synchronization Profile)
34 SyncML:格式化資訊同步規範(Synchronisation Mark-up Language Profile)
35 VDP:影像分享規範(Video Distribution Profile)
36 WAPB:基於藍芽點對點的WAP (Wireless Application Protocol Bearer) – 一個完全無用的協定。
HCI是Host Control Interface的簡寫。簡單來說,上層的這些Profile (軟體),利用HCI與底層的Bluetooth硬體,與另外一台裝置連接。如果裝置的雙方都有相同的Profile,就可以連接起來幹活了。
目前連接的方式(術語稱之為Transport)有UART、USB、SD、3-Wire UART四種。我們常見的接法就是主晶片使用UART連接Bluetooth晶片。這是最最簡單的接法,因為就等於使用 /dev/tty02 就可以完成通信了。
HCI 定義了四種封包,在主晶片與 BT模組之傳送資料:
1. Command : 0x01 使用 0x01 開頭的封包就是命令。
2. ACL:用於傳輸一般性資料具有基本的資料可靠性保證 (0x02)
3. SCO:用於語音資料的傳遞(x03)
4. Event:用於BT Module 回應 Host 的控制(0x04)
如果你找 INCLUDE FILE的定義,你會看到這樣的定義:
這些定義可以在 /include/net/bluetooth/hci.h 當中看到。如果沒有,可以先到BlueZ官網,下載最新版的SOURCE CODE,hci.h 在 ./lib 的目錄下面。
下面就先看一下HCI_COMMAND與HCI_EVENT在傳些甚麼東西:
CI 命令封包(Command Packet) 是由一個16 bits 的操作碼(Opcode)開始, 操作碼由兩部份組成 分別是 OGF (OpCode Group Field, 6 bits) 與 OCF (OpCode Command Field, 10 bits),
OGF 目前定義了 6 個 Group
當OGF與OCF 都為0 時則是一個 NOP 命令,在流量控制中可能會需要使用到。
接在Opcode 後的就是SIZE,這是說明BODY的總長度,所以BODY依照不同命令會有不同的長度。
要注意的是HCI的功能是透過UART,讓主晶片的CPU可以與藍芽晶片溝通。舉例而言,要對一個BT Module下達進入測試模式(Enable Device Under Test Mode)時,就可以使用 OGF =: 0x06。Protocol的細節可以參考藍芽Core Specification Section 7.6.3 Part E, Volume 2。
每當一個Command 下達給BT晶片之後,晶片會回應一個HCI Command Complete Event 給Host端表示完成命令的接收。

其實都是差不多的結構:
就是先送 Event Code、接上參數長度,然後依照這個長度,讀出所有的參數。大致上懂了HCI 的功能之後,接下來就可以回來玩玩這些已經寫好的命令。
首先先試試 hciconfig:
果然看到一些資訊,而且與上面說的這些理論值,可以對應得起來。由於顯示為DOWN,所以試試能不能UP:
因為硬體沒有開嗎? 於是由DESKTOP上面開啟Bluetooth。這裡有個疑問? 難道沒有命令可以打開Bluetooth硬體嗎? 這還要研究一下,總之hciconfig 無法開啟硬體就是了。接下來就有以下的畫面:
所以 Bluetooth DEVICE在哪裡? 原來是 hci0 。
這台PC是透過USB與藍芽晶片連接的。 其中藍牙晶片支援基礎率/增強資料率(BR/EDR),但是另外的BLE (低耗能)則沒有支持。
Mac Address D0-53-49 屬於光寶(Liteon Technology Corporation),BT模組應該是光寶製作的。
結果找到:
/usr/bin/hciattach
/usr/bin/hcidump
/usr/bin/hcitool
/use/bin/bluemoon
/usr/bin/bluetoothctl
/etc/bluetooth
/etc/dbus-1/system.d/bluetooth.conf
/etc/init.d/bluetooth
/etc/rc0.d/K01bluetooth
/etc/rc1.d/K01bluetooth
/etc/rc2.d/S01bluetooth
/etc/rc6.d/K01bluetooth
HCI這個名詞常常出現在Bluetooth的命令之中,所以先了解一下。
Bluetooth 基本上可以大致分為底層硬體的PHY (就是我們平常說的BT4.1, BT5.0) 與上層的應用Profile,目前已經有一堆Profile被定義:
1 A2DP : 藍牙立體聲音訊傳輸規範(Advanced Audio Distribution Profile )
2 ATT:(Attribute Profile)
3 AVRCP:音訊/影片遠端控制設定檔(Audio/Video Remote Control Profile)
4 BIP:基本圖像規範(Basic Imaging Profile)
5 BPP:基本列印規範(Basic Printing Profile)
6 CIP:ISDN規範(Common ISDN Access Profile)
7 CTP:無線電話規範(Cordless Telephony Profile)
8 DIP:裝置識別符號規範(Device ID Profile)
9 DUN:撥接網路規範(Dial-up Networking Profile)
10 FAX:傳真規範(Fax Profile)
11 FTP:檔案傳輸規範(File Transfer Profile)
12 GAVDP:影音傳送通用規範(Generic Audio/Video Distribution Profile)
13 GAP:通用存取規範(Generic Access Profile) – BLE 相關規範。
14 GATT:通用型連接規範(Generic Attribute Profile) – BLE 相關規範。
15 Generic Object Exchange Profile (GOEP)
16 Hard Copy Cable Replacement Profile (HCRP)
17 HDP:醫療設備規範(Health Device Profile )
18 HFP:手持裝置規範(Hands-Free Profile )
19 HID:人機介面規範(Human Interface Device Profile)
20 Headset Profile (HSP)
21 ICP:網內通訊規範(Intercom Profile )
22 LAP:網路訪問配置規範(LAN Access Profile)
23 MESH:MESH規範(Mesh Profile)
24 MAP:簡訊交換規範(Message Access Profile)
25 OBEX:泛用物件交換規範(OBject EXchange)
26 OPP:物件交換規範(Object Push Profile)
27 PAN:個人區域網路規範(Personal Area Networking Profile)
28 PBAP:電話簿存取規範(Phone Book Access Profile)
29 PXP:裝置接近規範(Proximity Profile)
30 SPP:序列埠規範(Serial Port Profile)
31 SDAP:服務搜尋規範(Service Discovery Application Profile)
32 SIM:SIM卡的遠端存取規範(SIM Access Profile, SAP, SIM or rSAP)
33 SYNCH:資訊同步規範(Synchronization Profile)
34 SyncML:格式化資訊同步規範(Synchronisation Mark-up Language Profile)
35 VDP:影像分享規範(Video Distribution Profile)
36 WAPB:基於藍芽點對點的WAP (Wireless Application Protocol Bearer) – 一個完全無用的協定。
目前連接的方式(術語稱之為Transport)有UART、USB、SD、3-Wire UART四種。我們常見的接法就是主晶片使用UART連接Bluetooth晶片。這是最最簡單的接法,因為就等於使用 /dev/tty02 就可以完成通信了。
HCI 定義了四種封包,在主晶片與 BT模組之傳送資料:
1. Command : 0x01 使用 0x01 開頭的封包就是命令。
2. ACL:用於傳輸一般性資料具有基本的資料可靠性保證 (0x02)
3. SCO:用於語音資料的傳遞(x03)
4. Event:用於BT Module 回應 Host 的控制(0x04)
如果你找 INCLUDE FILE的定義,你會看到這樣的定義:
typedef enum _HCI_PACKET_TYPE_ {
HCI_COMMAND = 0x01,
HCI_ACL = 0x02,
HCI_SCL = 0x03,
HCI_EVENT = 0x04
} HCI_PACKET_TYPE;
這些定義可以在 /include/net/bluetooth/hci.h 當中看到。如果沒有,可以先到BlueZ官網,下載最新版的SOURCE CODE,hci.h 在 ./lib 的目錄下面。
下面就先看一下HCI_COMMAND與HCI_EVENT在傳些甚麼東西:
HCI_COMMAND
先看一下HCI_COMMAND Packet Format,用C struct 可以這樣表示:
_HCI_PACKET_ {
union
{
unsigned short int code; // 16 bit
struct {
unsigned int ocf :10;
unsigned int ogf : 6;
} op;
}
unsigned char Size; // parameter total length
unsgined char* body; // context of parameters
} HCI_PACKET;
CI 命令封包(Command Packet) 是由一個16 bits 的操作碼(Opcode)開始, 操作碼由兩部份組成 分別是 OGF (OpCode Group Field, 6 bits) 與 OCF (OpCode Command Field, 10 bits),
OGF 目前定義了 6 個 Group
- 連結控制命令(Link Control Command), OGF =: 0x01
- 連結方式命令(Link Policy Command), OGF =: 0x02
- 控制器與基頻命令(Controller & Baseband Command), OGF =: 0x03
- 資訊參數(Informational Parameters), OGF =: 0x04
- 狀態參數(Status Parameters), OGF =: 0x05
- 測試命令(Testing Command), OGF =: 0x06
當OGF與OCF 都為0 時則是一個 NOP 命令,在流量控制中可能會需要使用到。
接在Opcode 後的就是SIZE,這是說明BODY的總長度,所以BODY依照不同命令會有不同的長度。
要注意的是HCI的功能是透過UART,讓主晶片的CPU可以與藍芽晶片溝通。舉例而言,要對一個BT Module下達進入測試模式(Enable Device Under Test Mode)時,就可以使用 OGF =: 0x06。Protocol的細節可以參考藍芽Core Specification Section 7.6.3 Part E, Volume 2。
每當一個Command 下達給BT晶片之後,晶片會回應一個HCI Command Complete Event 給Host端表示完成命令的接收。
HCI_EVENT
HCI_EVENT是BT晶片用來回應 HCI Command 的封包,基本結構如下:
HCI_EVENT Packet Format
其實都是差不多的結構:
typedef struct {
uint16_t handle; /* Handle & Flags (PB, BC) */
uint16_t dlen;
}
就是先送 Event Code、接上參數長度,然後依照這個長度,讀出所有的參數。大致上懂了HCI 的功能之後,接下來就可以回來玩玩這些已經寫好的命令。
首先先試試 hciconfig:
root@luke-G50:/etc/bluetooth# hciconfig <Enter>
hci0: Type: BR/EDR Bus: USB
BD Address: D0:53:49:00:FB:6A ACL MTU: 1022:8 SCO MTU: 183:5
DOWN
RX bytes:574 acl:0 sco:0 events:30 errors:0
TX bytes:368 acl:0 sco:0 commands:30 errors:0
果然看到一些資訊,而且與上面說的這些理論值,可以對應得起來。由於顯示為DOWN,所以試試能不能UP:
root@luke-G50:/etc/bluetooth# hciconfig hci0 up
Can't init device hci0: Operation not possible due to RF-kill (132)
因為硬體沒有開嗎? 於是由DESKTOP上面開啟Bluetooth。這裡有個疑問? 難道沒有命令可以打開Bluetooth硬體嗎? 這還要研究一下,總之hciconfig 無法開啟硬體就是了。接下來就有以下的畫面:
root@luke-G50:/etc/bluetooth# hciconfig hci0 up
root@luke-G50:/etc/bluetooth# hciconfig hci0
hci0: Type: BR/EDR Bus: USB
BD Address: D0:53:49:00:FB:6A ACL MTU: 1022:8 SCO MTU: 183:5
UP RUNNING PSCAN ISCAN
RX bytes:1190 acl:0 sco:0 events:67 errors:0
TX bytes:1076 acl:0 sco:0 commands:67 errors:0
所以 Bluetooth DEVICE在哪裡? 原來是 hci0 。
這台PC是透過USB與藍芽晶片連接的。 其中藍牙晶片支援基礎率/增強資料率(BR/EDR),但是另外的BLE (低耗能)則沒有支持。
Mac Address D0-53-49 屬於光寶(Liteon Technology Corporation),BT模組應該是光寶製作的。
BlueZ 的研讀紀錄(一): 安裝
自從Linux可以在Windows 10下面跑之後,學習Linux就方便了不少,今天想試試能不能在這樣的環境當中,讀到Device。
實驗的對象是想試試看在這樣的環境當中,能不能讀到 Bluetooth介面?
先到 /dev 下面看一下,發現似乎沒有相關的Device Name。

在安裝BlueZ之前必須要安裝一些開發環境,為了比較產生版本上的問題,先將系統更新到最新版本:
這兩個命令都執行了非常久,做了很多的更新。
接下來安裝一些相關的指令:
這大約是安裝開發環境。最後便可以安裝BlueZ了:

由於就在/dev目錄之下,看一下 Device Name 有甚麼變化?

結果是沒有甚麼變化。 接著執行 hcidump,發現還要繼續安裝新的Package:
# sudo apt install bluez-hcidump <Enter>
實驗的對象是想試試看在這樣的環境當中,能不能讀到 Bluetooth介面?
先到 /dev 下面看一下,發現似乎沒有相關的Device Name。

在安裝BlueZ之前必須要安裝一些開發環境,為了比較產生版本上的問題,先將系統更新到最新版本:
# sudo apt-get update <Enter># sudo apt-get upgrade <Enter>
這兩個命令都執行了非常久,做了很多的更新。
接下來安裝一些相關的指令:
# sudo apt-get install -y git bc libusb-dev libdbus-1-dev libglib2.0-dev libudev-dev libical-dev libreadline-dev autoconf bison flex libssl-dev <Enter>
這大約是安裝開發環境。最後便可以安裝BlueZ了:
# sudo apt install bluez <Enter>

順利安裝完成。
由於就在/dev目錄之下,看一下 Device Name 有甚麼變化?

結果是沒有甚麼變化。 接著執行 hcidump,發現還要繼續安裝新的Package:
# sudo apt install bluez-hcidump <Enter>
訂閱:
意見 (Atom)